9 Regressão por splines e modelos aditivos generalizados
9.1 Regressão por splines
Os métodos de regressão não-paramétrica ou semi-paramétrica, são geralmente superiores se comparados aos paramétricos dada sua alta flexibilidade. Dentre estes destacam-se os modelos aditivos generalizados (generalized aditive models - GAM). O GAM foi introduzido por Hastie et al. (1987) e consiste em uma extensão dos modelos lineares generalizados (Generalized Linear Models - GLM), com preditores lineares somados de funções de suavização não paramétricas dos preditores, geralmente de forma não-linear. Para falar sobre modelos aditivos generalizados é necessário primeiro introduzir a regressão por funções de passo, os polinômios por partes e a regressão por splines.
9.1.1 Regressão por funções de passo ou escada
A regressão por funções de passo ou escada consideram a divisão do domínio do preditor, estimando uma constante para cada divisão. É um modelo que se parece com uma regressão por árvore de decisão para uma variável, porém os algoritmos e, portanto, modelos obtidos são distintos. Ademais, as árvores de decisão consideram múltiplas variáveis, enquanto a regressão por função de passo é para casos simples.
Para realizar a divisão no domínio pode-se utilizar de funções indicadoras \(I(.)\) que recebem 1 caso a condição seja satisfeita e 0 caso contrário. São, portanto, criadas divisões a partir da definição de nós no espaço do preditor, \(\xi_1, \xi_2, \ldots, \xi_G\), onde \(G\) é o número de nós (JAMES et al., 2013). Por exemplo, para dois nós:
\[ \begin{matrix} C_1(x) = I(x<\xi_1)\\ C_2(x) = I(\xi_1 \leq x < \xi_2)\\ C_3(x) = I(x \geq \xi_2)\\. \end{matrix} \]
Para qualquer valor de \(x\) é importante observar que \(C_1(x)+C_2(x)+C_3(x)=1\). Um modelo de regressão por funções de passo para dois nós pode ser definido conforme Equação 9.1. Pode-se observar que o resultado estimado será \(\beta_0+\beta_1\) ou \(\beta_0+\beta_2\) ou \(\beta_0+\beta_3\), para \(C_1(x)\) ou \(C_2(x)\) ou \(C_3(x)\) unitário, respectivamente (JAMES et al., 2013).
\[ \hat{y}_i=\beta_0+\beta_1C_1(x_i)+\beta_2C_2(x_i)+\beta_3C_3(x_i) \tag{9.1}\]
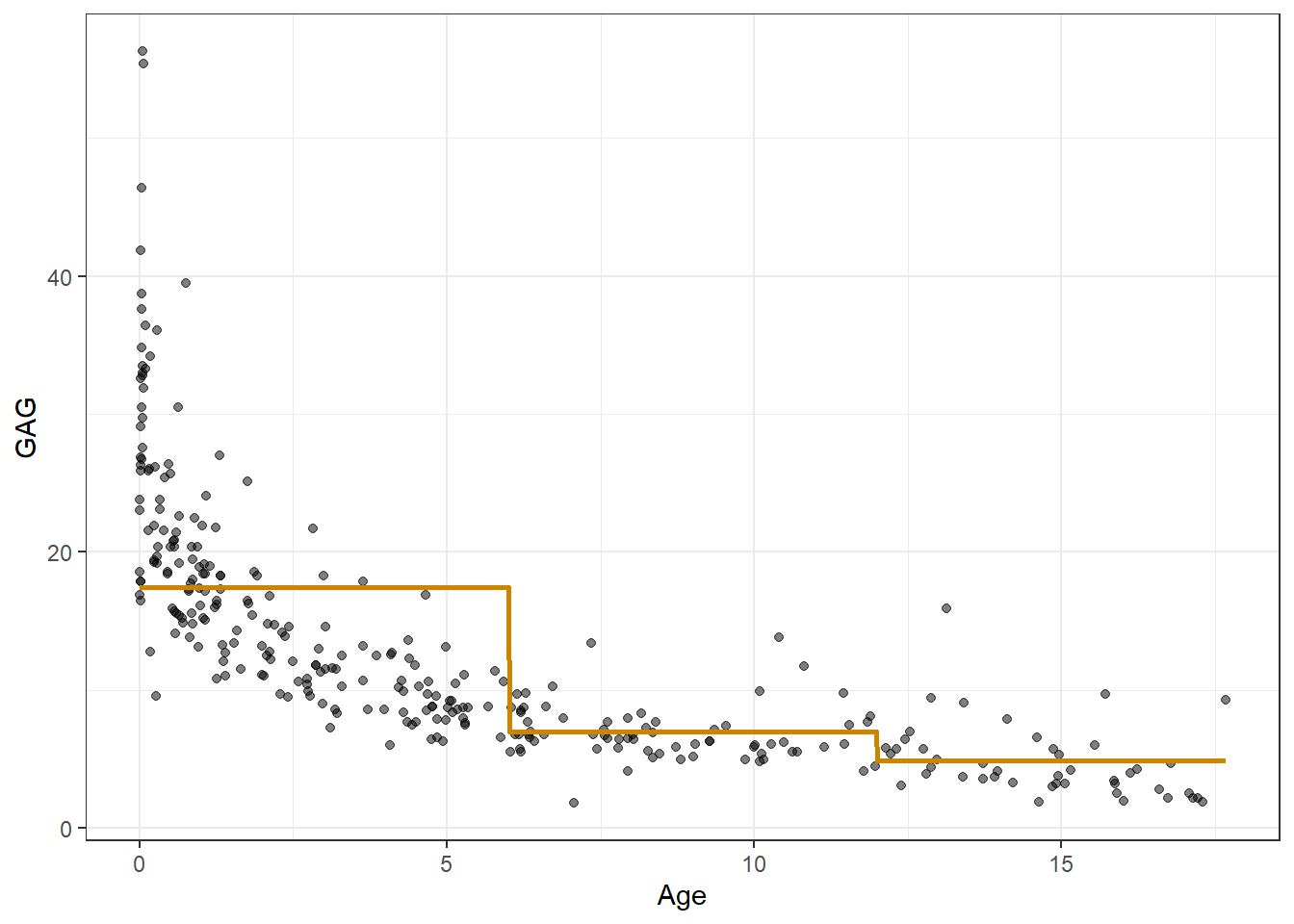
Considerando \(\beta_0 = \overline{y}\), \(\beta_j=(\overline{y}|\xi_{j-1}\leq x <\xi_{j})-\overline{y}\), ou seja, cada coeficiente que multiplica as funções indicadoras consiste na diferença entre a média das observações na divisão e a média geral. Ao final, o valor previsto consiste em uma constante que é a média das observações de treino da região. Seja um conjunto de dados da concentração do químico GAG na urina de crianças de 0 a 17 anos. Um modelo de regressão por funções de passo considerando duas divisões, nas idades de 8 e 16 anos, é plotado abaixo.
Obviamente modelos mais complexos podem ser considerados, por exemplo, modelos polinomiais para cada região.
9.1.2 Polinômios por partes
Uma regressão polinomial cúbica por partes considerando apenas um nó ou divisão consiste em um modelo definido da forma da Equação 9.2.
\[ \hat{y}_i = \biggl\{ \begin{matrix} \beta_{01} + \beta_{11}x_i + \beta_{21}x_i^2 + \beta_{31}x_i^3, x_i < \xi\\ \beta_{02} + \beta_{12}x_i + \beta_{22}x_i^2 + \beta_{32}x_i^3, x_i \ge \xi, \end{matrix} \tag{9.2}\]
onde \(\xi\) consiste em nó ou divisão no domínio da variável regressora \(x\) e os coeficientes diferem para cada uma das regiões obtidas. Para o exemplo de concentração de GAG em urina de adolescentes, um modelo de regressão polinomial cúbico por partes, considerando dois nós para idades de 6 e 12, é plotado na Figura 9.2.
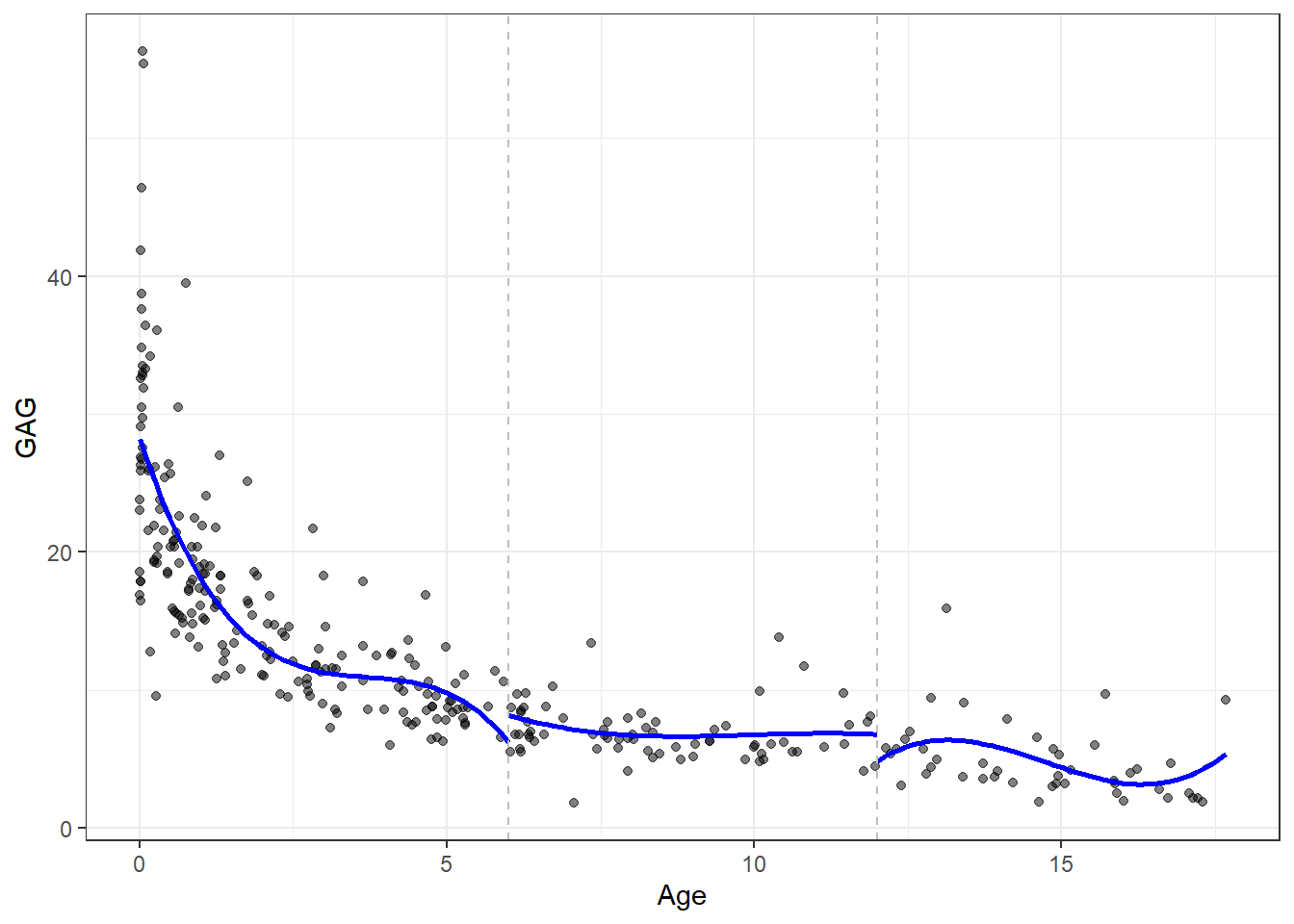
Um problema deste modelo é a descontinuidade e falta de suavidade nas divisões. Para garantir a continuidade, uma restrição de igualdade na transição pode ser considerada. Uma forma interessante de definir os nós é a partir dos percentis, de forma que cada contenha um número igual de observações.
9.1.3 Regressão por spline cúbica
Considerando uma função de uma variável \(f(x)\), \(x\) \(\in \mathbb{R}^1\), seja \(h_m(x)\) a \(m\)-ésima transformação de \(x\), \(m=1, \ldots, M\). Um modelo considerando esta transformação pode ser representado conforme Equação 9.3.
\[ \begin{matrix} f(x) = \sum_{i=1}^M \beta_{(m-1)} h_m(x) \\ \end{matrix} \tag{9.3}\]
As funções de transformação \(h_m(X)\) para um modelo de regressão por spline cúbico com, por exemplo, dois nós, são geralmente \(h_1(x) = 1\), \(h_2(x) = x\), \(h_3(x) = x^2\), \(h_4(x) = x^3\), \(h_5(x) = (x - \xi_1)_+^3\), \(h_6(x) = (x - \xi_2)_+^3\), onde \(\xi_1\) e \(\xi_2\) são nós e \(t_+\) denota a parte positiva desses domínios, conforme Equação 9.4.
\[ (x - \xi)_+^3 = \biggl\{ \begin{matrix} \text{0, }x< \xi\\ (x - \xi)^3\text{, } x\ge\xi \end{matrix} \tag{9.4}\]
Considerando essas transformações na Equação anterior, a função obtida é um polinômio cúbico por partes. Tal função pode ser escrita segundo a Equação 9.5, sendo uma função cúbica para todo o domínio adicionada de termos cúbicos para as divisões realizadas no domínio.
\[ \hat{y}_i=\beta_0 + \beta_1x_i + \beta_2x_i^2 + \beta_3x_i^3 + \beta_4(x_i-\xi_1)_+^3 + \beta_5(x_i-\xi_2)_+^3 \tag{9.5}\]
Para garantir a continuidade da função resultante nos nós e considerar os quatro parâmetros para cada uma das três regiões resultantes, podem ser definidas restrições de igualdade das funções nos nós. Para uma transição suave nos nós, a continuidade nas derivadas de primeira e segunda ordem também podem ser adicionadas. O modelo resultante tem seis parâmetros. De forma geral, uma spline cúbica terá \(4 + g\) graus de liberdade, onde \(g\) é o número de nós (JAMES et al., 2013). Para o mesmo problema de previsão de GAG em urina de adolescentes, considerando três nós nas idades de 4, 8 e 12 anos, o gráfico da Figura 9.3 plota uma estimativa por regressão via spline cúbica.
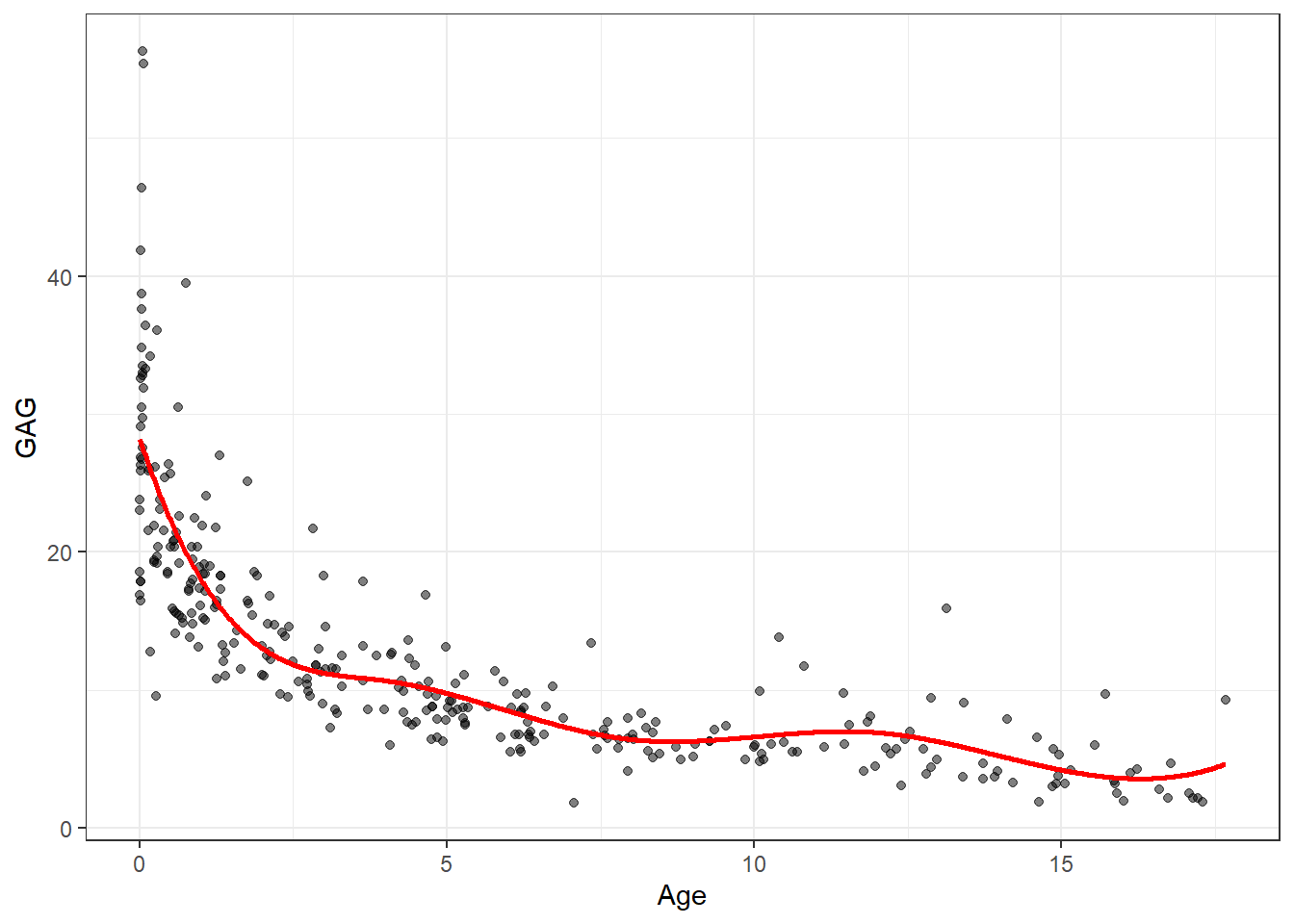
Pode-se observar que, para o exemplo estudado, há um volume maior de observações para os primeiros anos de idade. Uma escolha mais razoável para os nós seria a definição destes a partir da distribuição das observações no domínio da variável regressora, de forma a garantir um número aproximadamente igual de observações entre os nós. Tomando os quantis de 25, 50 e 75%, tem-se o modelo atualizado na Figura 9.4.
9.1.4 Regressão por spline natural cúbica
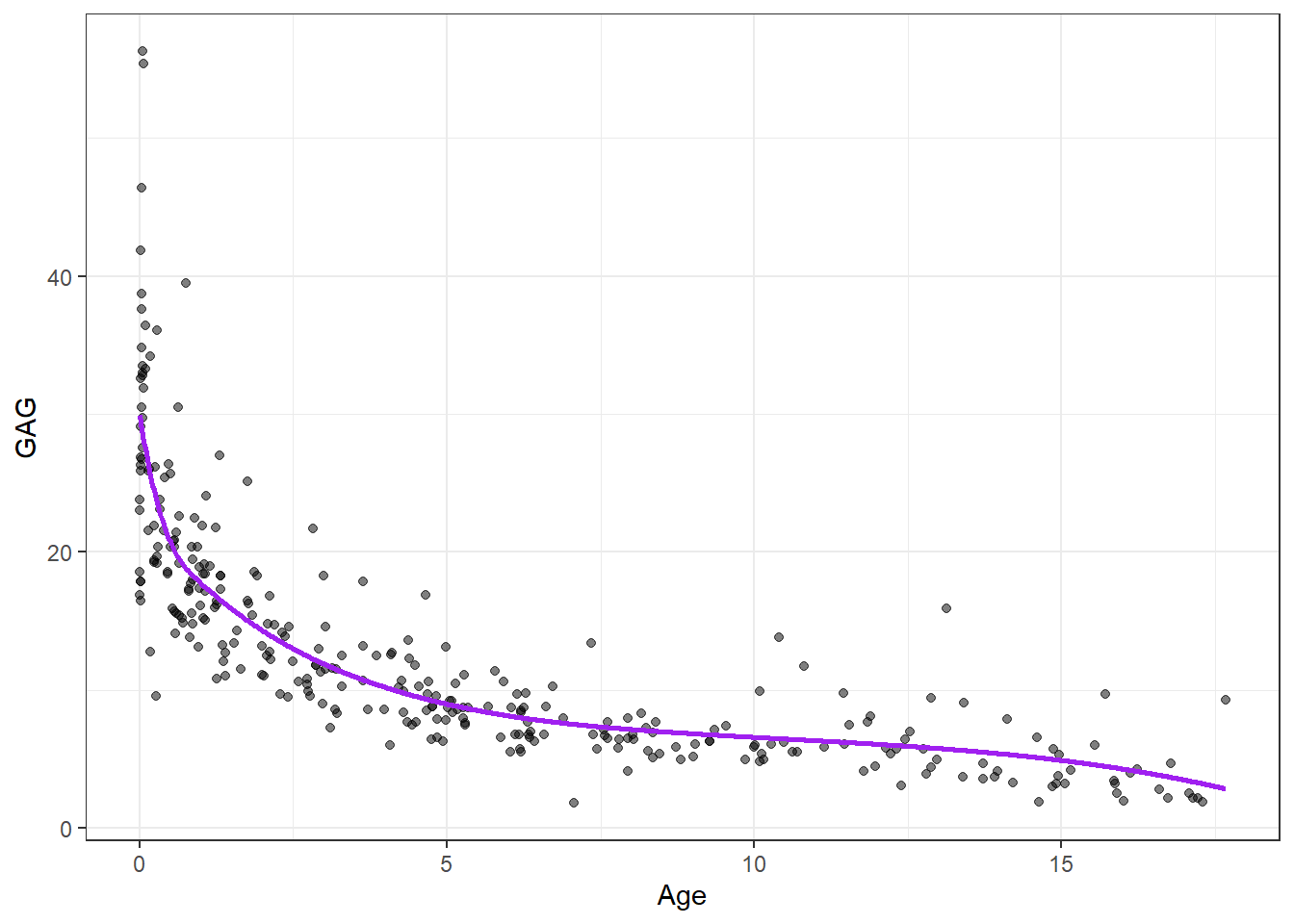
Outro detalhe considerado na regressão por spline cúbica é a linearização nas caudas. Tal modificação visa diminuir a variabilidade nos extremos do modelo. Para tal deve-se apenas excluir os termos envolvendo as transformações quadrática e cúbica para todo o domínio de \(x\), isto é, \(h_3(x) = x^2\), \(h_4(x) = x^3\). Este modelo é conhecido como regressão por spline natural cúbica (JAMES et al., 2013). Para o exemplo do GAG obtém-se o resultado apresentado na Figura 9.5.
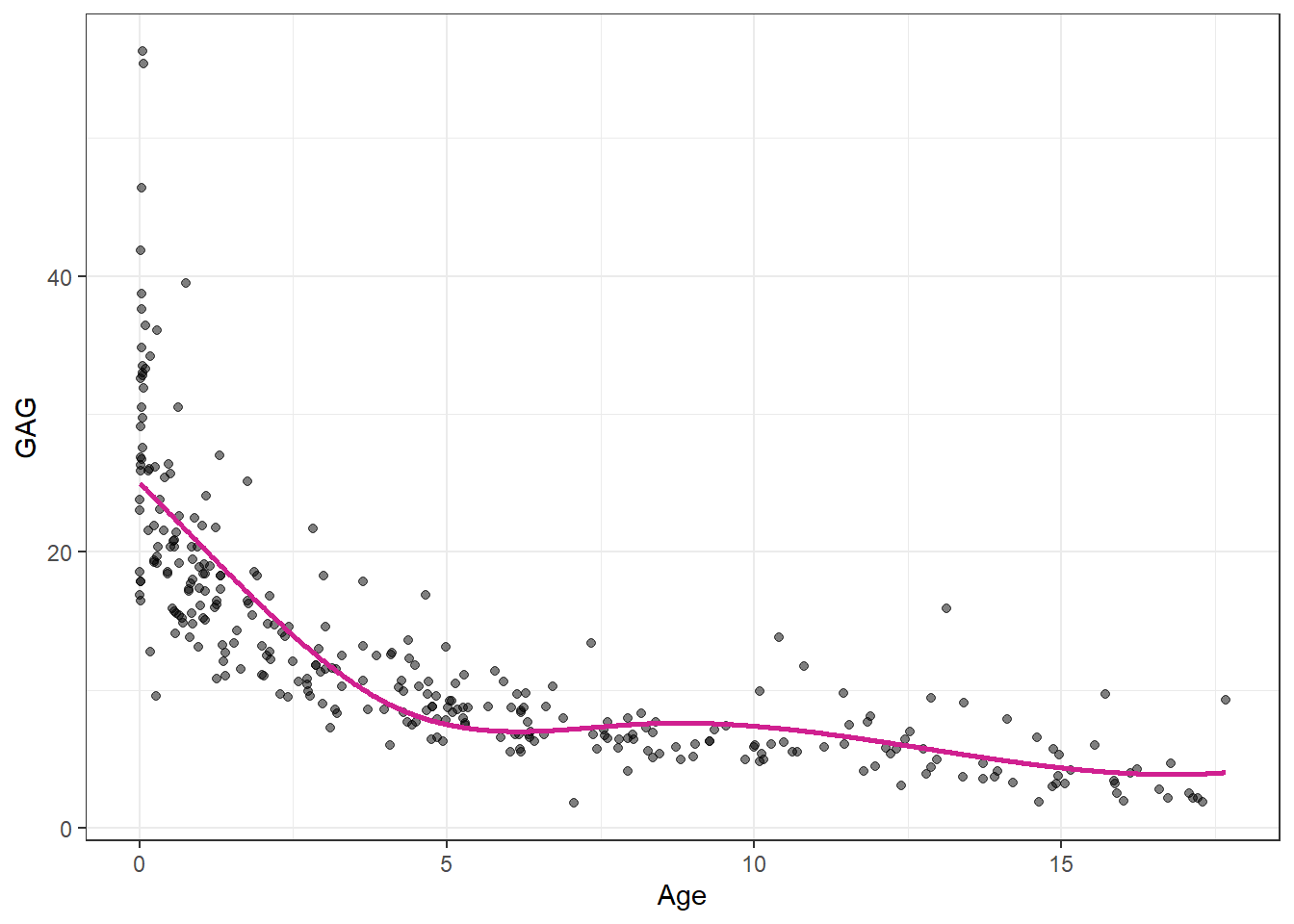
9.1.5 Suavização de modelos de regressão por spline
A realização da estimativa de um modelo de regressão por spline é feita minimizando uma função perda quadrática, isto é,
\[ L=\sum_{i=1}^N(y_i-f(x_i))^2\text{.} \]
Porém, ao se utilizar de um modelo de regressão por spline, é possível fazer tal função perda chegar a um valor nulo, interpolando todas observações de treino, o que implicará, obviamente em um ajuste perfeito para os dados de treino. Porém, tal modelo apresentará alta variância e, consequentemente, baixo desempenho ao ser aplicado em dados futuros. Para evitar tal problema, um termo de suavização é adicionado à função perda em otimização, conforme Equação 9.6.
\[ L=\sum_{i=1}^N(y_i-f(x_i))^2 + \lambda\int f''(t)^2dt, \tag{9.6}\]
onde o termo \(\int f''(t)^2dt\) mede a soma dos quadrados da variação na inclinação da função, de forma a controlar o grau de rugosidade do modelo. Se \(\lambda \rightarrow 0\), tem-se o modelo mais rugoso possível, que seria um modelo com \(N\) nós, ou seja, um nó para cada observação de treino, apresentando \(g+2\) graus de liberdade, o qual apresentará alta variância. Por outro lado, se \(\lambda \rightarrow \infty\), tem-se um modelo linear que seria o mais suave possível, apresentando apenas dois termos e, portanto, 2 graus de liberdade. O parâmetro de suavização \(\lambda\) controla o grau de suavidade do modelo e, portanto, o número efetivo de graus de liberdade. A escolha de \(\lambda\) deve ser realizada por validação cruzada e grid search (JAMES et al., 2013).
Existem outros métodos de regressão por splines os quais não serão abordados aqui. Dentre estes destacam-se a regressão local. O leitor é convidado a ler as referências utilizadas neste texto para mais informações.
9.2 Modelos aditivos generalizados (GAM)
Conforme visto, os modelos de regressão por splines são em função de uma variável. Os modelos aditivos generalizados visam a extensão dos modelos de regressão por splines para o caso de múltiplas variáveis regressoras de interesse. Os modelos aditivos generalizados visam estender os modelos de regressão múltipla,
\[ \hat{y}=\beta_0+\beta_1x_1+\beta_2x_2+\ldots+\beta_kx_k, \]
substituindo os coeficientes lineares \(\beta_j\), por uma função não-linear do termo \(x_j\), \(f(x_j)\). Tal função pode ser, por exemplo, uma spline natural. Um modelo GAM pode ser descrito, portanto, conforme Equação 9.7.
\[ \hat{y}=\beta_0+\beta_1f_1(x_1)+\beta_2f_2(x_2)+\ldots+\beta_kf_k(x_k), \tag{9.7}\]
Seja um conjunto com 99 observações de distintos campos de petróleo dos EUA contendo o preço médio do barril de petróleo em função do grau de pureza e do percentual de enxofre. Deseja-se prever o preço médio do barril em função de tais variáveis.
Considerando um GAM a partir de splines naturais em função dos dois parâmetros, pode-se aproximar um modelo para preço do barril do Petróleo.
O GAM estimado para tal caso é plotado na Figura 9.6.
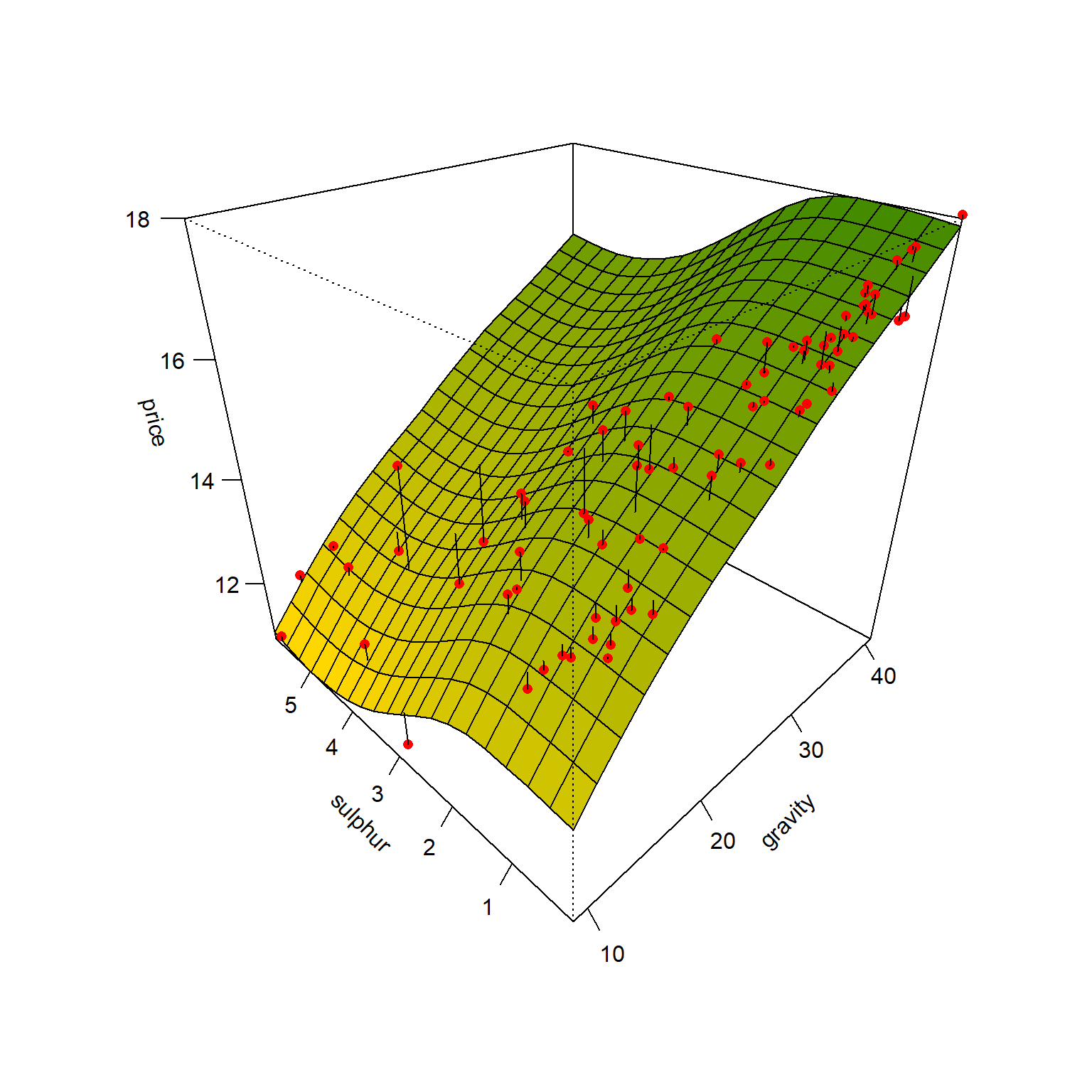
Dentre algumas limitações dos modelos aditivos generalizados pode-se destacar a impossibilidade de incluir diretamente interações entre os preditores, uma vez que os modelos são aditivos. Entretanto, é possível gerar variáveis adicionais que consistem no produto de variáveis preditoras para considerar a interação.
9.3 Implementações em R
A seguir serão expostas as implementações necessárias para obter os resultados do capítulo.
9.3.1 Modelos de regressão via spline para dados de nível de GAG na urina de crianças
Carregando pacotes.
library(MASS)
library(ggplot2)
library(dplyr)
library(splines)
library(AER)
library(gam)
library(modelsummary)
library(GGally)Dados.
data(GAGurine)
# ?GAGurine
dados <- GAGurine
head(dados)Visualização inicial.
pdata <- ggplot(dados, aes(x=Age, y=GAG)) +
geom_point(alpha=0.5) +
theme_bw()
pdataSeparando dados de treino e teste.
set.seed(45)
tr <- round(0.8*nrow(dados))
treino <- sample(nrow(dados), tr, replace = F)
dados.treino <- dados[treino,]
dados.teste <- dados[-treino,]Modelo de regressão via função de passo ou escada (step function), considerando como nós as idades de 6 e 12 anos.
lm_pas <- lm(GAG ~ 1 + I(1*(Age<6)) + (1*I(Age>= 6 & Age<12)) + I(1*(Age>=12)), dados.treino)Visualizando o modelo obtido.
x_grid <- seq(min(dados$Age), max(dados$Age), length=1000)
pred_pas <- predict(lm_pas, newdata = data.frame(Age=x_grid))
pred_pas <- data.frame(Age=x_grid,
GAG=pred_pas)pdata + geom_line(data=pred_pas, aes(x=Age,y=GAG),
col = "orange3", lwd=1) Polinômios por partes.
lm_l6 <- lm(GAG ~ Age + I(Age^2) + I(Age^3),
dados.treino |> filter(Age<6))
lm_b612 <- lm(GAG ~ Age + I(Age^2) + I(Age^3),
dados.treino |> filter(Age>=6 & Age<12))
lm_g12 <- lm(GAG ~ Age + I(Age^2) + I(Age^3),
dados.treino |> filter(Age>=12))Visualizando modelo.
x_grid_l6 <- seq(min(dados$Age),6, length=50)
pred_l6 <- predict(lm_l6, newdata = data.frame(Age=x_grid_l6))
pred_l6 <- data.frame(Age=x_grid_l6,
GAG=pred_l6)
x_grid_b612 <- seq(6,12, length=50)
pred_b612 <- predict(lm_b612, newdata = data.frame(Age=x_grid_b612))
pred_b612 <- data.frame(Age=x_grid_b612,
GAG=pred_b612)
x_grid_g12 <- seq(12, max(dados$Age), length=50)
pred_g12 <- predict(lm_g12, newdata = data.frame(Age=x_grid_g12))
pred_g12 <- data.frame(Age=x_grid_g12,
GAG=pred_g12)pdata + geom_line(data=pred_l6, aes(x=Age,y=GAG),
col = "blue", lwd=1) +
geom_line(data=pred_b612, aes(x=Age,y=GAG),
col = "blue", lwd=1) +
geom_line(data=pred_g12, aes(x=Age,y=GAG),
col = "blue", lwd=1) +
geom_vline(xintercept = c(6,12), lty=2,col="grey")Spline natural cúbica.
knots <- quantile(dados$Age)[2:4]
lm_cub_ <- lm(GAG ~ Age + I((Age-knots[1])^3*(Age>=knots[1])) +
I((Age-knots[2])^3*(Age >= knots[2])) +
I((Age-knots[3])^3*(Age >= knots[3])),
dados.treino)Visualizando modelo.
pred_cub_ <- predict(lm_cub_, newdata = data.frame(Age=x_grid))
pred_cub_ <- data.frame(Age=x_grid,
GAG=pred_cub_)pdata + geom_line(data=pred_cub_, aes(x=Age,y=GAG),
col = "violetred", lwd=1)O modelo de spline natural é mais complexo que o realizado anteriormente, uma vez que considera as derivadas de primeira ordem seja constante e a de segunda ordem seja nula nos nós extremos. Recomenda-se usar a função ns do pacote splines para obtenção do modelo.
ns1 <- lm(GAG ~ ns(Age, knots = knots), data = dados.treino)Visualizando modelo.
ns_ <- predict(ns1, newdata = data.frame(Age=x_grid))
pred_ns <- data.frame(Age=x_grid,
GAG=ns_)pdata +
geom_line(data=pred_ns, aes(x=Age,y=GAG),
col = "violetred", lwd=1)Suavização de splines é uma boa escolha uma vez que seleciona o número ideal de nós (ou graus de liberdade) por grid search e validação cruzada.
ssp1 <- smooth.spline(dados.treino$Age,
dados.treino$GAG,
df=30)
ssp2 <- smooth.spline(dados.treino$Age,
dados.treino$GAG,
cv=T) ### cv = T faz validacao cruzada via LOO
ssp2$dfpred_df30 <- predict(ssp1)
pred_df30 <- data.frame(Age=pred_df30$x,
GAG=pred_df30$y)
pred_smoo <- predict(ssp2)
pred_smoo <- data.frame(Age=pred_smoo$x,
GAG=pred_smoo$y)pdata +
geom_line(data=pred_df30, aes(x=Age,y=GAG),
col = "lightblue", lwd=1) +
geom_line(data=pred_smoo, aes(x=Age,y=GAG),
col = "navy", lwd=1)9.3.2 Modelos generalizados aditivos para preço médio do barril de petróleo
Carregando dados.
data(USCrudes)
# ?USCrudes
dados <- USCrudesVisualizando dados.
glimpse(dados)datasummary_skim(dados)ggpairs(dados) + theme_bw()set.seed(11)
tr <- round(0.8*nrow(dados))
treino <- sample(nrow(dados), tr, replace = F)Modelo generalizado aditivo.
gam1 <- gam(price~s(gravity) + s(sulphur), family = gaussian, dados[treino,])O modelo é suavizado e os graus de liberdade para cada variável considerada podem ser obtidos.
gam1$nl.dfGráficos para observar os efeitos individuais.
par(mfrow = c(1,2))
plot(gam1, se=TRUE, col ="red", lwd = 2)Visualizando modelo GAM obtido.
xs <- seq(min(dados$gravity), max(dados$gravity), length = 20)
ys <- seq(min(dados$sulphur), max(dados$sulphur), length = 20)
xys <- expand.grid(xs,ys)
colnames(xys) <- c("gravity", "sulphur")
zs <- matrix(predict(gam1, xys), nrow = length(xs))
n.cols <- 100
palette <- colorRampPalette(c("gold", "chartreuse4"))(n.cols)
zfacet <- zs[-1, -1] + zs[-1, -20] + zs[-20, -1] + zs[-20, -20]
facetcol <- cut(zfacet, n.cols)
par(mfrow = c(1,1))
p1 <- persp(x=xs, y=ys, z=zs, theta=-45, phi=30, ticktype='detailed',
xlab="gravity", ylab="sulphur", zlab="price", col = palette[facetcol])
obs <- with(dados[-treino,], trans3d(gravity,sulphur,price,p1))
pred <- with(dados[-treino,], trans3d(gravity,sulphur,predict(gam1,newdata = dados[-treino,]), p1))
points(obs, col = "red", pch = 16)
segments(obs$x, obs$y, pred$x, pred$y)O desempenho dos modelos não foi calculado para os dados de teste. Sugere-se fazê-lo de forma similar ao realizado nos capítulos anteriores.
Referências
Hastie, Trevor, and Robert Tibshirani. “Generalized additive models: some applications.” Journal of the American Statistical Association 82.398 (1987): 371-386.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning (Vol. 112, p. 18). New York: springer.