5 Suavização exponencial
5.1 Suavização exponencial simples
A suavização exponencial consiste em uma média ponderada das observações anteriores, com peso decaindo exponencialmente à medida que as observações ficam mais distantes no tempo.
A previsão para a suavização exponencial simples pode ser denotada conforme Equação 5.1
\[ \hat y_{T+1|T} = \alpha y_T + \alpha(1-\alpha)y_{T-1} + \alpha(1-\alpha)^2y_{T-2}+... \tag{5.1}\]
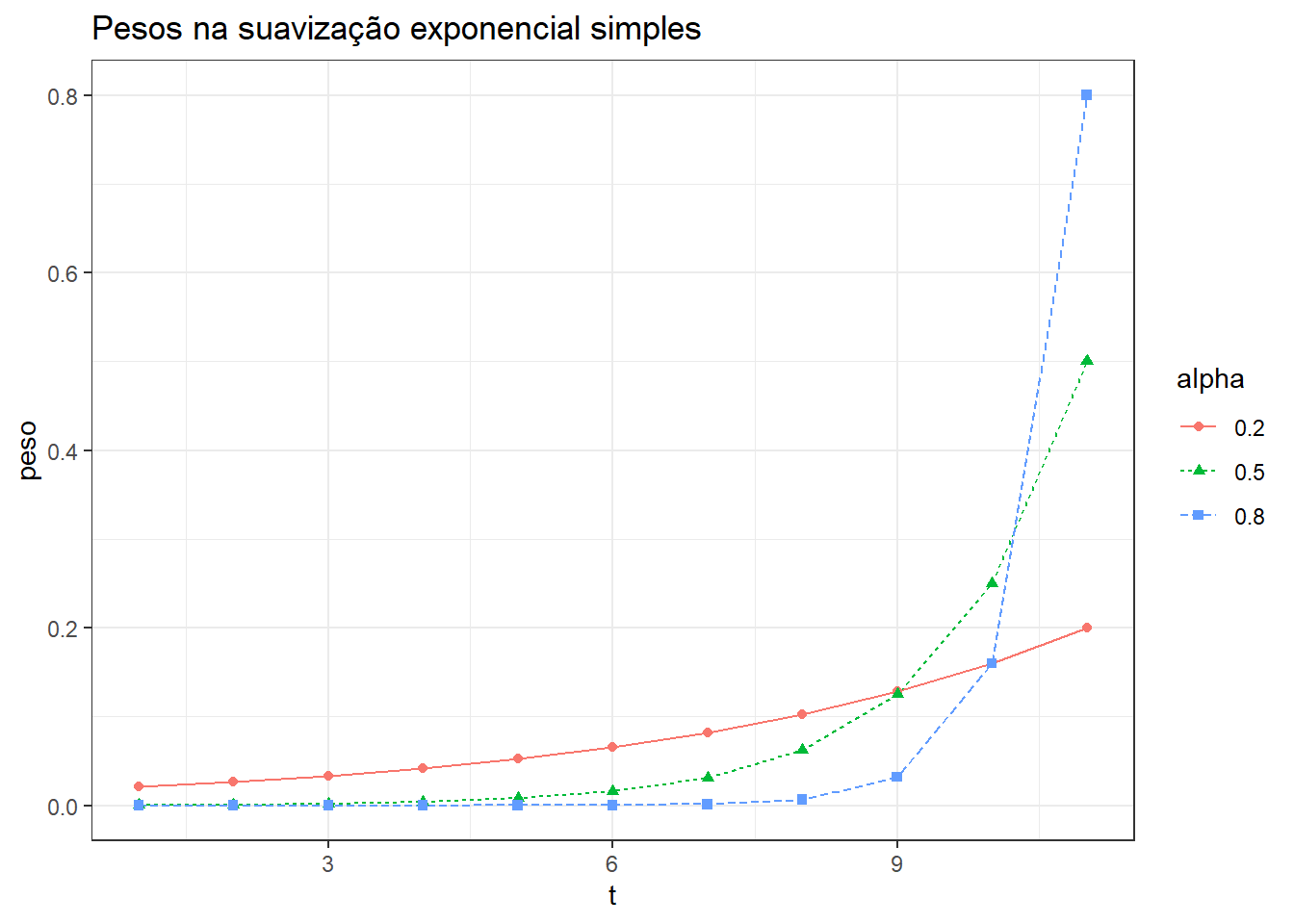
onde \(0< \alpha <1\) consiste no parâmetro de suavização. A previsão um passo à frente consiste em uma média ponderada das observações anteriores, \(y_1,...,y_T\), com taxa de decrescimento dos pesos controlada pelo parâmetro \(\alpha\). A Tabela 5.1 expõe os pesos para as cinco últimas observações para distintos valores de \(\alpha\). Observa-se que a soma dos pesos é próxima de 1.
| Observação | \(\alpha=0.2\) | \(\alpha=0.5\) | \(\alpha=0.8\) |
|---|---|---|---|
| \(y_T\) | 0.200000 | 0.500000 | 0.800000 |
| \(y_{T-1}\) | 0.160000 | 0.250000 | 0.160000 |
| \(y_{T-2}\) | 0.128000 | 0.125000 | 0.032000 |
| \(y_{T-3}\) | 0.102400 | 0.062500 | 0.006400 |
| \(y_{T-4}\) | 0.081920 | 0.031250 | 0.001280 |
| \(y_{T-5}\) | 0.065536 | 0.015625 | 0.000256 |
A Figura 5.1 expõe os mesmos pesos plotados segundo o tempo. Observa-se que quanto maior o \(\alpha\), maior a taxa de decrescimento dos pesos da última observação em relação às anteriores.
O modelo exposto para prever a observação futura pode ser descrito sempre considerando a última observação e a previsão desta, conforme Equação 5.2.
\[ \hat y_{T+1|T} = \alpha y_T +(1-\alpha)\hat y_{T|T-1} \tag{5.2}\]
De forma similar, os valores ajustados para a série ficam conforme Equação 5.3.
\[ \hat y_{t+1|t} = \alpha y_t +(1-\alpha)\hat y_{t|t-1}, \tag{5.3}\]
para \(t=1,...,T\).
Seja \(l_0\) o valor estimado para a primeira observação, \(t=1\), então:
\[ \begin{align} \hat y_{2|1} &= \alpha y_1 +(1-\alpha) l_0 \\ \hat y_{3|2} &= \alpha y_2 +(1-\alpha) \hat y_{2|1} \\ \hat y_{4|3} &= \alpha y_3 +(1-\alpha) \hat y_{3|2} \\ \vdots \\ \hat y_{T|T-1} &= \alpha y_{T-1} +(1-\alpha) \hat y_{T-1|T-2} \\ \hat y_{T+1|T} &= \alpha y_{T} +(1-\alpha) \hat y_{T|T-1} \\ \end{align} \]
Observe que cada equação pode ser substituída na posterior, conforme Equação 5.4.
\[ \begin{align} \hat y_{3|2} &= \alpha y_2 +(1-\alpha) [\alpha y_1 +(1-\alpha) l_0] \\ &= \alpha y_2 + \alpha(1-\alpha)y_1 +(1-\alpha)^2 l_0\\ \hat y_{4|3} &= \alpha y_3 +(1-\alpha)[\alpha y_2 + \alpha(1-\alpha) y_1 +(1-\alpha)^2 l_0] \\ &= \alpha y_3 +\alpha(1-\alpha) y_2 +\alpha(1-\alpha)^2 y_1 +(1-\alpha)^3 l_0 \\ \vdots \\ \hat y_{T+1|T} &= \sum_{j=0}^{T-1} \alpha (1-\alpha)^j y_{T-j}+ (1-\alpha)^T l_0 \\ \end{align} \tag{5.4}\]
Como o último termo fica muito pequeno para \(T\) grande, então a equação fica conforme o modelo apresentado inicialmente.
A representação em componentes também é comum para a suavização exponencial, sendo o caso simples expresso na Equação 5.5.
\[ \begin{align} \text{Equação de previsão: } \hat y_{t+h} &= l_t\\ \text{Equação de suavização: } l_t &= \alpha y_t + (1-\alpha)l_{t-1},\\ \end{align} \tag{5.5}\]
onde \(l_t\) consiste no nível no período \(t\) e \(\hat y_{t+h} = l_t\) a previsão no período \(t+h\).
Se \(h=0\), tem-se o valor ajustado para \(y_t\), enquanto se \(t=T\) e \(h \geq1\), tem-se a previsão para além dos dados observados ou disponíveis para treino ou estimativa da série. Fazendo \(l_t = \hat y_{t+1|t}\) e \(l_{t-1} = \hat y_{t|t-1}\), tem-se o modelo ponderado já exposto. Tal representação não é tão útil para o caso simples, porém, quando considerados termos de tendência e suavização, será. O modelo simples, até aqui explicitado é recomendado para casos sem tendência e sazonalidade.
A Figura 5.2 expõe o resultado da suavização exponencial simples para a série do IPCA no Brasil a partir de 2019. Os parâmetros estimados, \(\alpha\) e \(l_0\), expostos na Tabela 5.2 foram estimados minimizando a soma dos quadrados dos erros para as estimativas um passo à frente.
| term | estimate |
|---|---|
| alpha | 0,5722074 |
| l[0] | 0,3963222 |
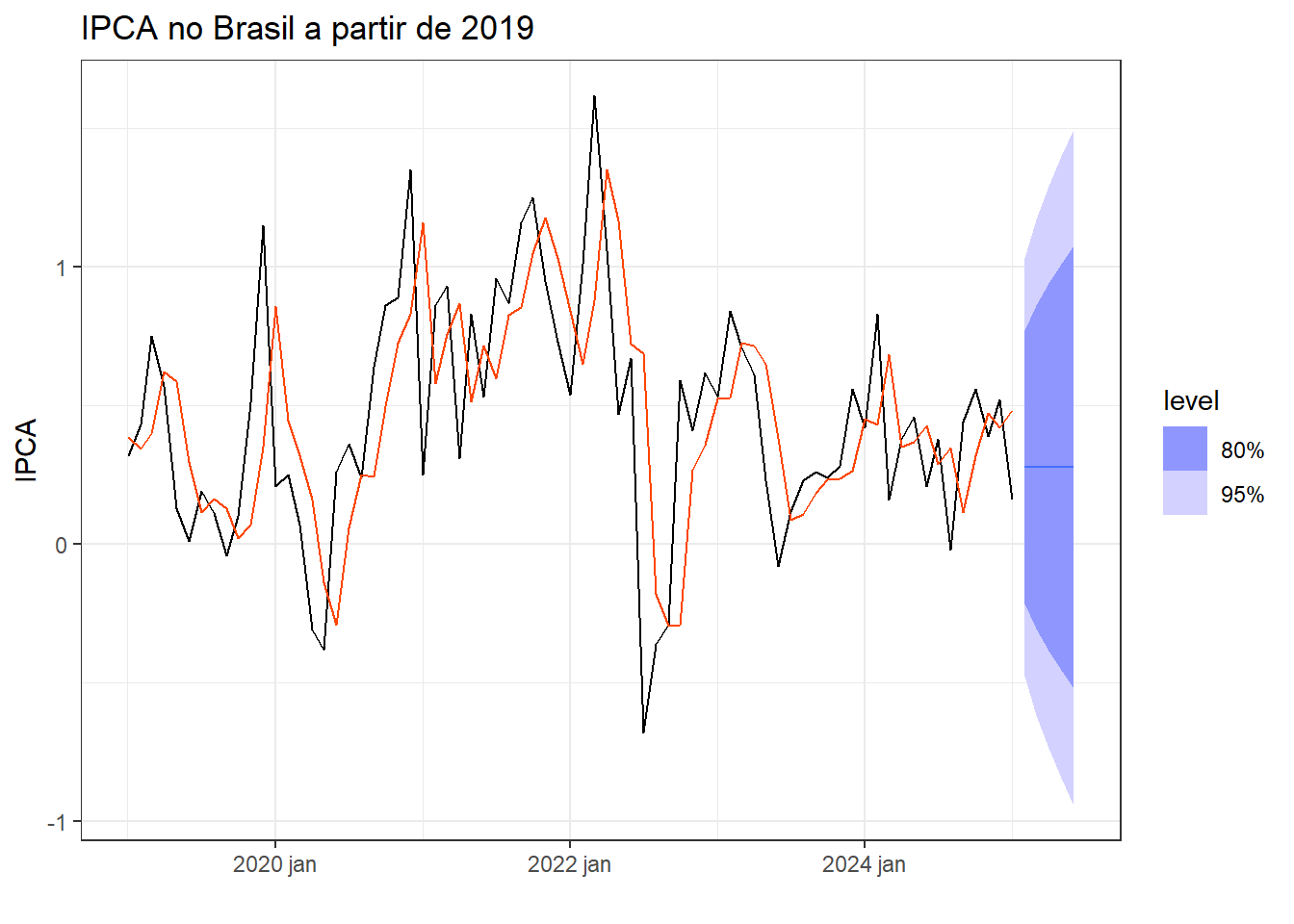
A Tabela 5.3 apresenta os valores ajustados \(\hat y_t\) para as últimas observações da série.
| Data | Variação | y_hat |
|---|---|---|
| 2025 fev | 1,31 | 0,30 |
| 2025 mar | 0,56 | 0,88 |
| 2025 abr | 0,43 | 0,70 |
| 2025 mai | 0,26 | 0,54 |
| 2025 jun | 0,24 | 0,38 |
| 2025 jul | 0,26 | 0,30 |
5.2 Suavização exponencial com tendência
Em casos com tendência pode-se aplicar o método de Holt (2004), o qual considera uma equação para o nível, \(l_t\), uma para a tendência, \(b_t\), e a de previsão, \(\hat y_{t+h|t}\), conforme Equação 5.6.
\[ \begin{align} \text{Equação de previsão: } \hat y_{t+h} &= l_t + hb_t\\ \text{Equação do nível: } l_t &= \alpha y_t + (1-\alpha)(l_{t-1}+b_{t-1})\\ \text{Equação de tendência: } b_t &= \beta^*(l_t-l_{t-1})+(1-\beta^*)b_{t-1} \end{align} \tag{5.6}\]
Neste caso \(l_t\) é uma média ponderada da observação \(y_t\) e da previsão um passo a frente, dada por \(l_{t-1}+b_{t-1}\). A equação de tendência, \(b_t\), consiste em uma média ponderada da tendência no tempo \(t\), baseada em \(l_t-l_{t-1}\), e na estimativa anterior da tendência, \(b_{t-1}\).
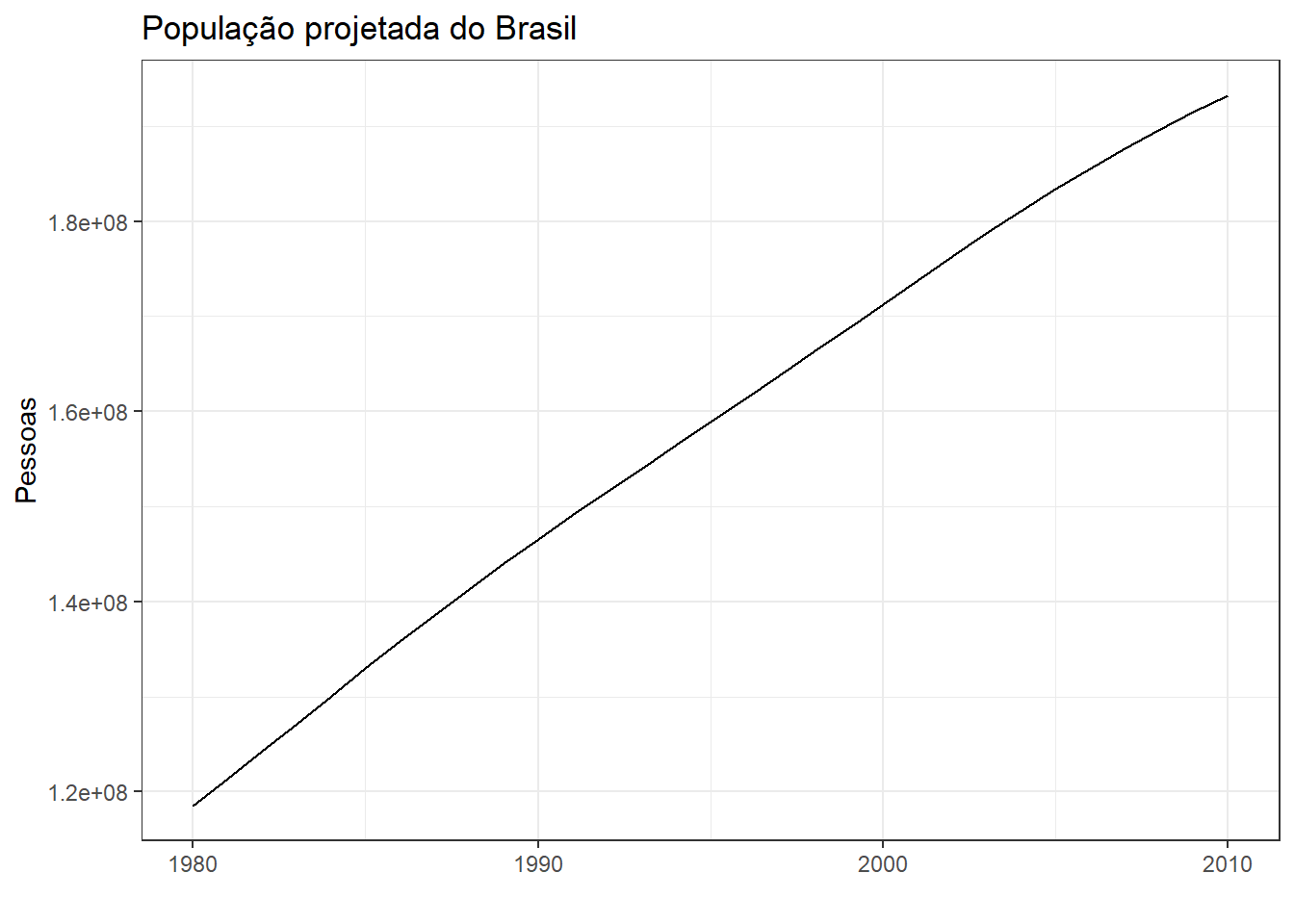
A Figura 5.3 expõe a série anual da população projetada para o Brasil até 2010, revisada em 2008, disponível em IBGE. Observa-se tendência de crescimento próxima de linear.
A Tabela 5.4 expõe os parâmetros estimados de suavização exponencial com tendência para a série da populaçao projetada do Brasil.
| Termo | Estimativa |
|---|---|
| alpha | 1,00 |
| beta | 0,44 |
| l[0] | 116948789,80 |
| b[0] | 2842713,24 |
5.2.1 Suavização exponencial com tendência amortecida
Um problema do método de Holt (2004) para suavização exponencial com tendência é que ele costuma apresentar uma estimativa linear que em longos horizontes de previsão que não se confirma. Uma opção é a abordagem de Gardner e Mckenzie (1985) que propõe amortecer as previsões. O método inclui o parâmetro de amortecimento \(0<\phi<1\).
\[ \begin{align} \text{Equação de previsão: } \hat y_{t+h} &= l_t + (\phi+\phi^2+...+\phi^h)b_t\\ \text{Equação do nível: } l_t &= \alpha y_t + (1-\alpha)(l_{t-1}+\phi b_{t-1})\\ \text{Equação de tendência: } b_t &= \beta^*(l_t-l_{t-1})+(1-\beta^*)\phi b_{t-1} \end{align} \]
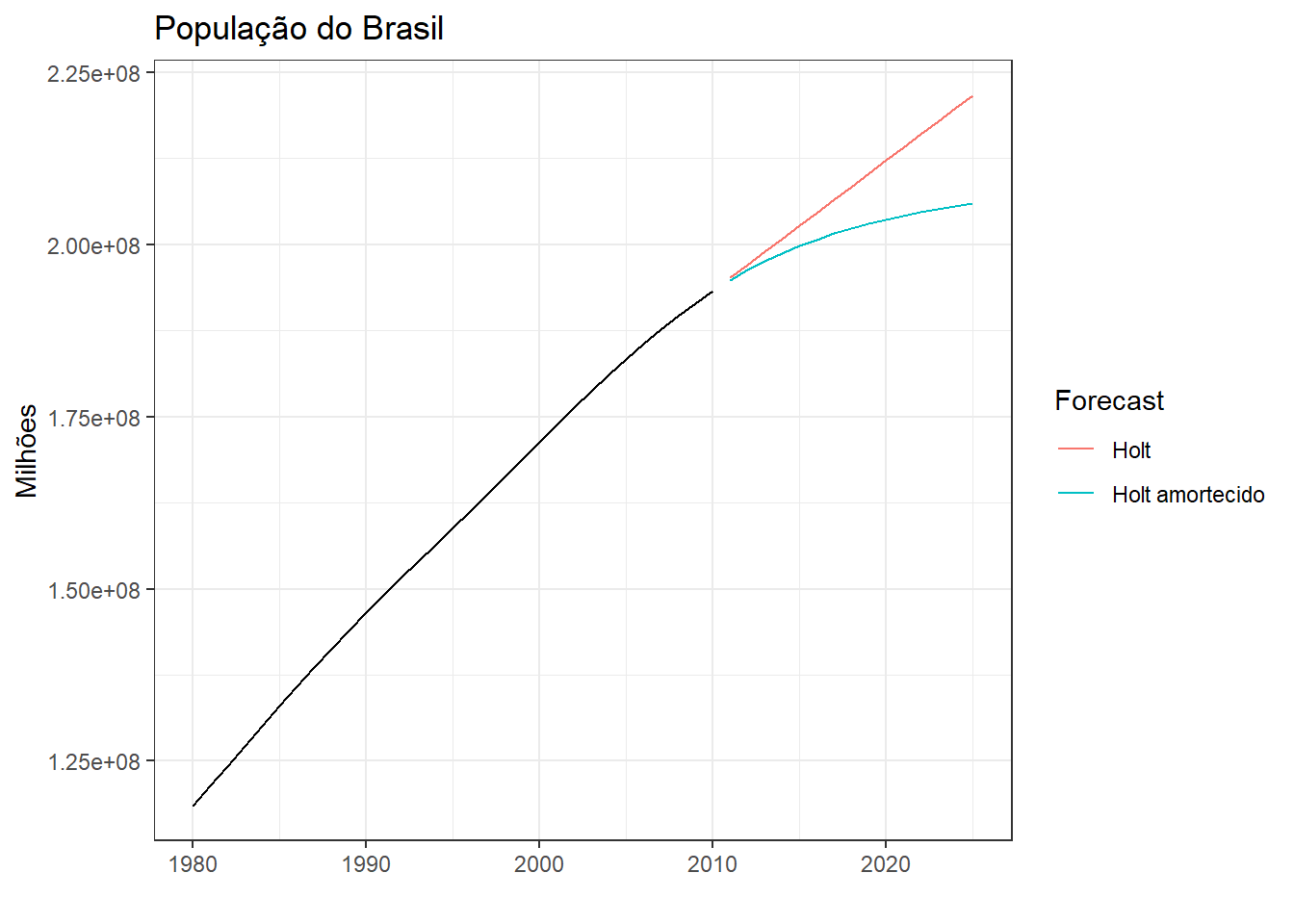
Caso \(\phi=1\), então tem-se o método de Holt já exposto. O método tende a gerar previsões com tendência não linear para curtos períodos que se tornam constantes em longos horizontes à frente das observações. A Figura 5.4 expõe as previsões 15 anos à frente para a população do Brasil considerando os dados projetados até 2010. Observa-se que o método de Holt projetaria 216 milhões de pessoas em 2022, enquanto o mesmo amortecido projetaria 210,8 milhões para o mesmo ano. Foi considerado neste caso \(\phi=0,97\). Dados já observados do censo de 2022 indicam que a população do Brasil neste ano atingiu 210,3 milhões de pessoas.
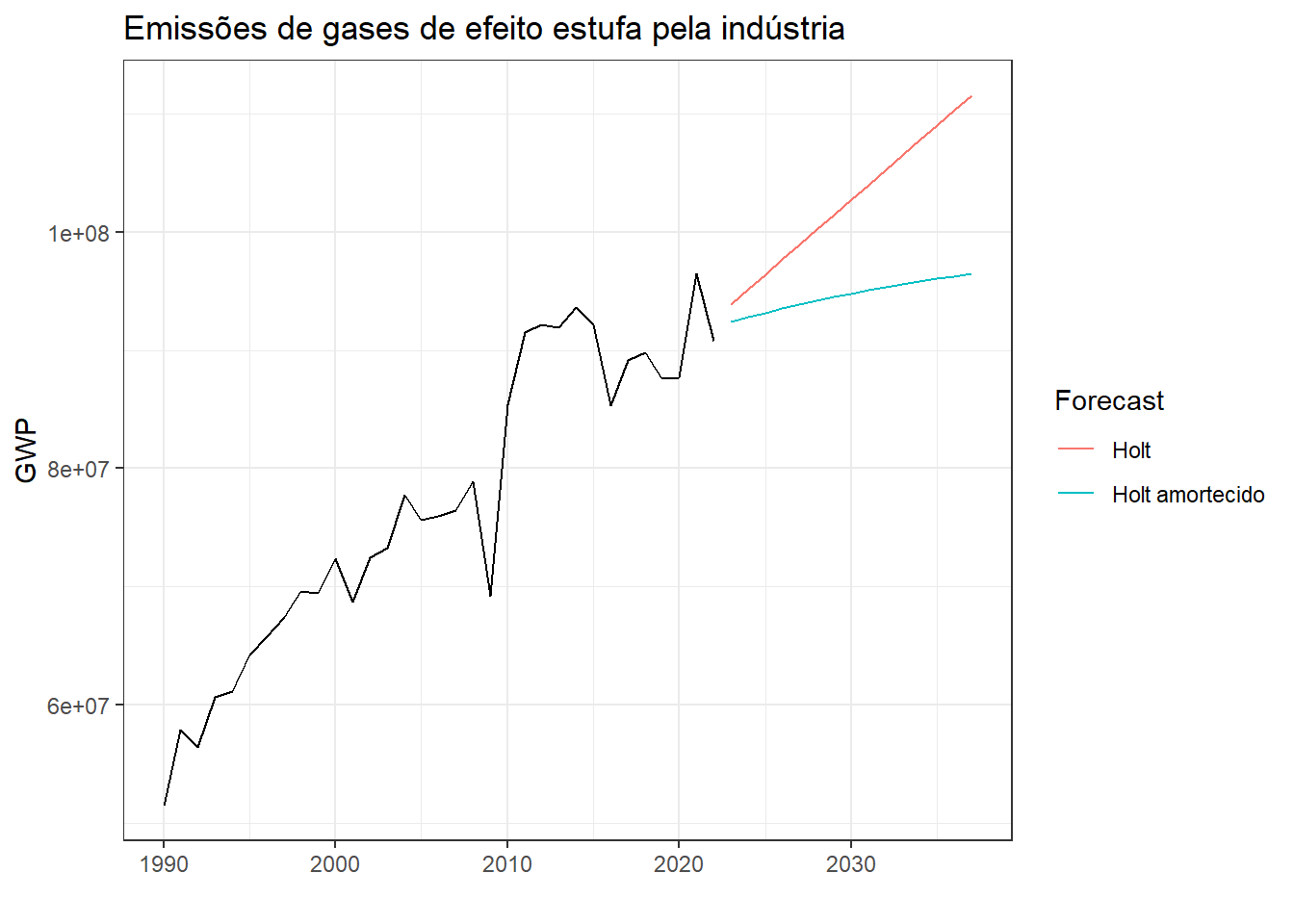
A Figura 5.5 expõe os resultados das previsões obtidas pelos mesmos métodos aplicados à série anual de emissão de gases de efeito estufa pela indústria, em Gg de CO2 equivalente, disponível em SIRENE - Sistema de Registro Nacional de Emissões. Foi considerado um \(\phi = 0,90\) para o caso com amortecimento. O amortecimento é importante, uma vez que o método Holt apresenta geralmente tendência acentuada, com inclinação com mais peso em relação ao observado nos últimos anos, que pode não se confirmar a médio prazo.
5.3 Suavização exponencial com sazonalidade
Holt (2004) e Winters (1960) adicionaram a sazonalidade na suavização exponencial. Logo, além das equações de previsão, nível e tendência, o método inclui uma equação adicional para a sazonalidade. O método considera ambos os casos aditivo e multiplicativo.
O método Holt-Winters aditivo é denotado conforme a Equação 5.7.
\[ \begin{align} \text{Equação de previsão: } \hat y_{t+h} &= l_t + hb_t + s_{t+h-m(k+1)}\\ \text{Equação do nível: } l_t &= \alpha (y_t-s_{t-m}) + (1-\alpha)(l_{t-1}+b_{t-1})\\ \text{Equação de tendência: } b_t &= \beta^*(l_t-l_{t-1})+(1-\beta^*)b_{t-1}\\ \text{Equação de sazonalidade: } s_t &= \gamma(y_t-l_{t-1}-b_{t-1})+(1-\gamma)s_{t-1}, \end{align} \tag{5.7}\]
onde \(k\) consiste na parte inteira de \((h−1)/m\) que garante que a estimativa dos índices sazonais usados para previsão vêm do último período sazonal da série. A equação de nível consiste em uma média ponderada entre a observação ajustada sazonalmente, \(y_t-s_{t-m}\), e a previsão não sazonal, \(l_{t-1}+b_{t-1}\), para o tempo \(t\). A equação de tendência não muda e a sazonal considera uma média móvel do índice sazonal atual, \(y_t-l_{t-1}-b_{t-1}\), e do mesmo período da estação anterior, \(s_{t-1}\).
O caso multiplicativo é exposto na Equação 5.8.
\[ \begin{align} \text{Equação de previsão: } \hat y_{t+h} &= (l_t + hb_t) s_{t+h-m(k+1)}\\ \text{Equação do nível: } l_t &= \alpha \frac{y_t}{s_{t-m}} + (1-\alpha)(l_{t-1}+b_{t-1})\\ \text{Equação de tendência: } b_t &= \beta^*(l_t-l_{t-1})+(1-\beta^*)b_{t-1}\\ \text{Equação de sazonalidade: } s_t &= \gamma \frac {y_t}{(l_{t-1}-b_{t-1})}+(1-\gamma)s_{t-1}, \end{align} \tag{5.8}\]
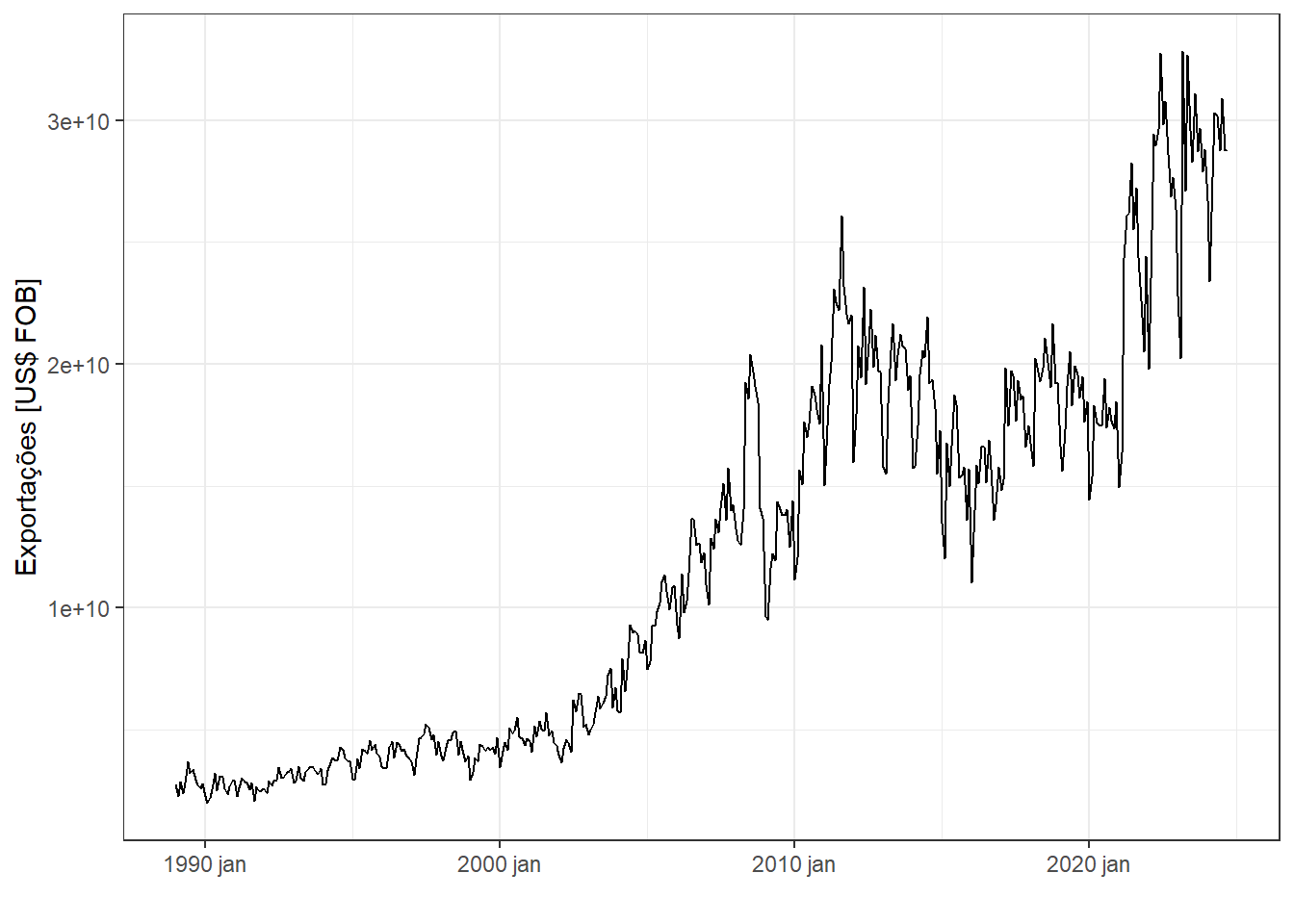
A Figura 5.6 plota a série temporal de exportações do Brasil em US$ FOB, disponível em Resultados do Comércio Exterior Brasileiro - Dados Consolidados. Observa-se em geral tendência de crescimento, estagnação de 2011 a 2021, dada a crise político-econômica e a pandemia, seguida de nova tendência de crescimento nos anos pós-pandemia.
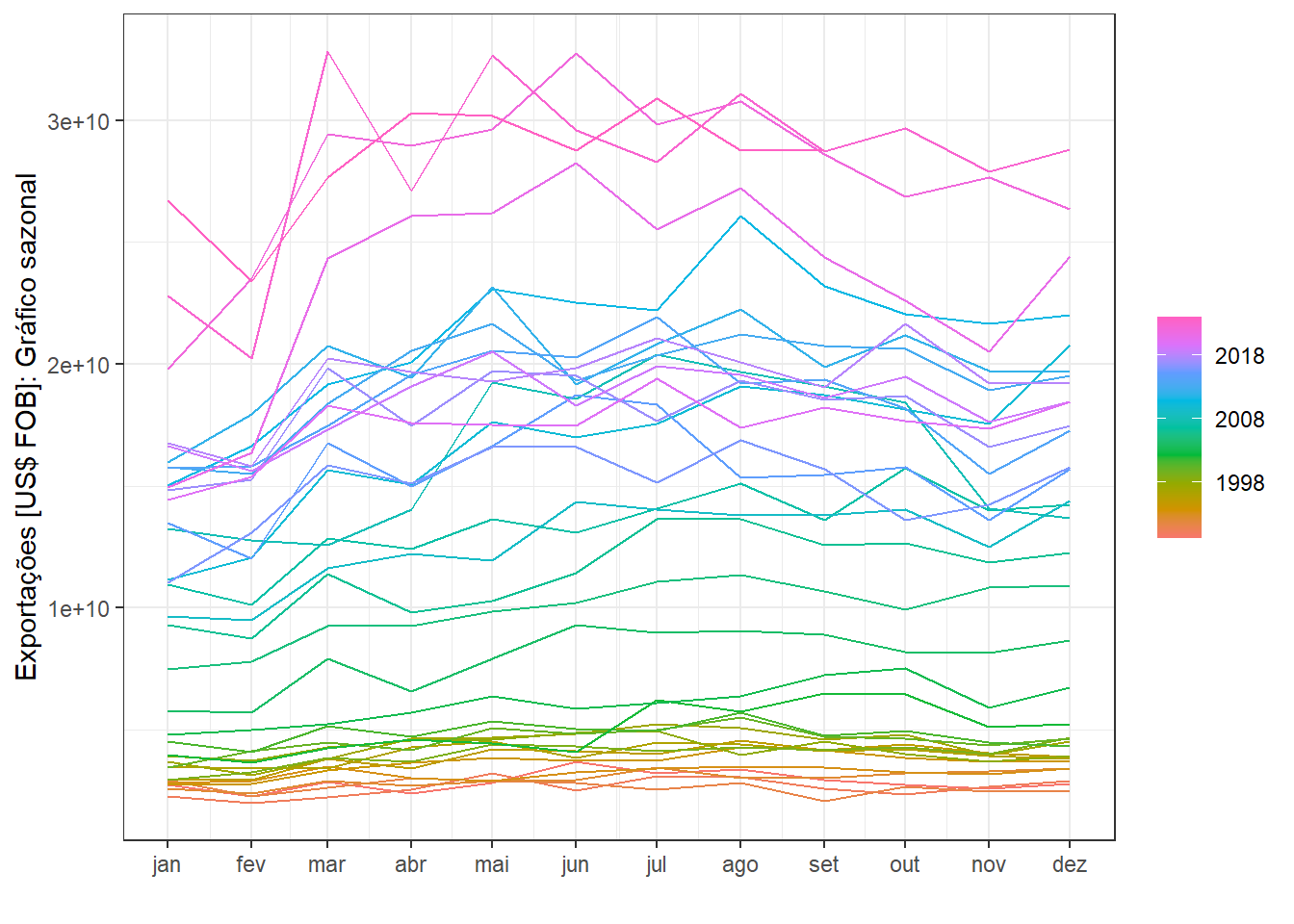
A Figura 5.7 expõe o gráfico sazonal da mesma série. O padrão cíclico não é tão claro, mas, especialmente nos últimos anos, nota-se maior volume de exportações de março a agosto.
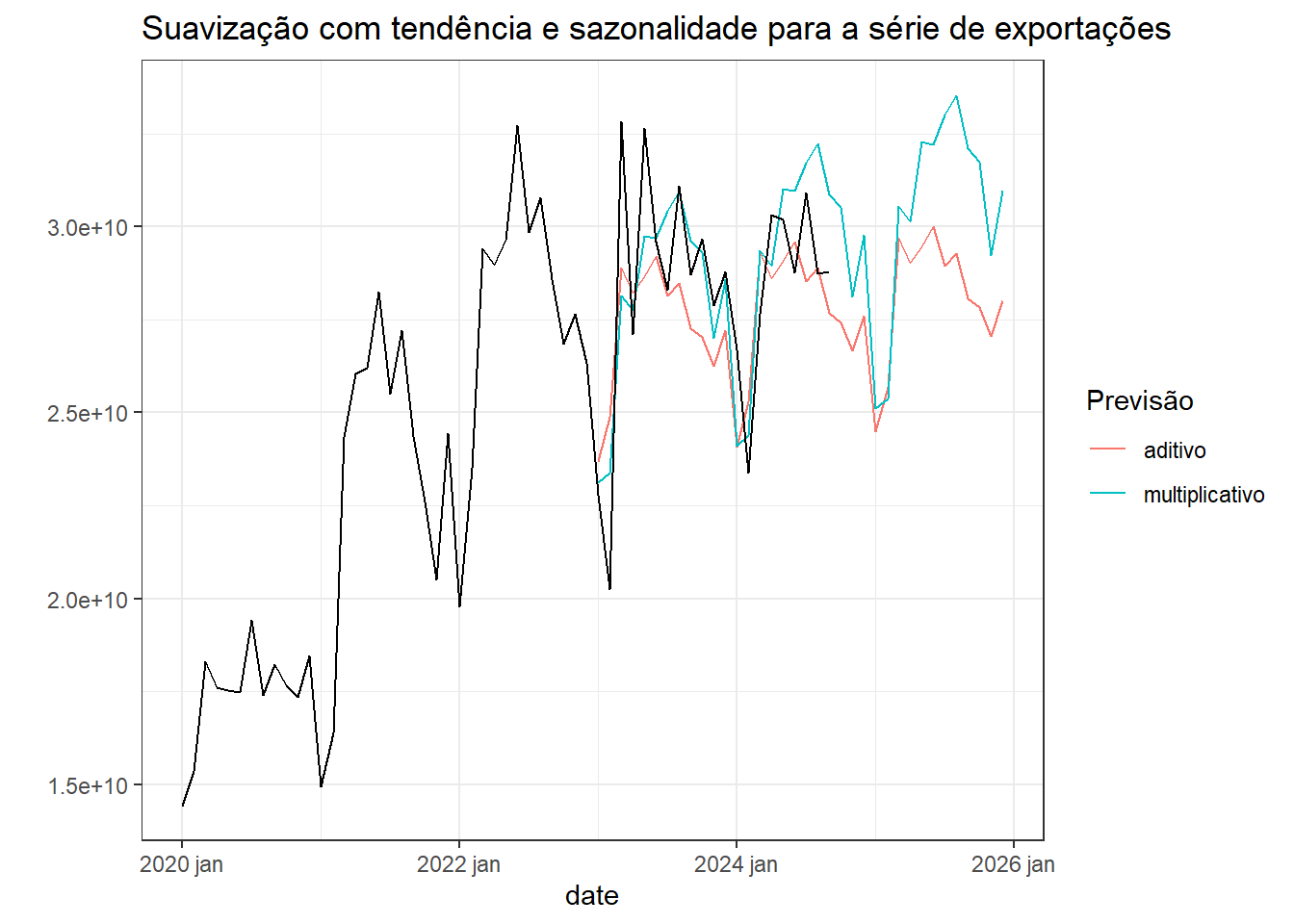
A Figura 5.8 expõe modelos de suavização exponencial com tendência e sazonalidade para a série de exportações do Brasil. Os modelos foram estimados considerando dados de até 2022, sendo as previsões realizadas para 3 anos à frente. O resultado foi plotado a partir de 2020, para melhor visualização.
5.3.1 Suavização exponencial com tendência amortecida e sazonalidade
O método de Holt-Winters também pode considerar o amortecimento. O caso multiplicativo geralmente fornece bons resultados, sendo descrito conforme Equação 5.9.
\[ \begin{align} \text{Equação de previsão: } \hat y_{t+h} &= [l_t + (\phi+\phi^2+...+\phi^h)b_t] s_{t+h-m(k+1)}\\ \text{Equação do nível: } l_t &= \alpha \frac{y_t}{s_{t-m}} + (1-\alpha)(l_{t-1}+\phi b_{t-1})\\ \text{Equação de tendência: } b_t &= \beta^*(l_t-l_{t-1})+(1-\beta^*)\phi b_{t-1}\\ \text{Equação de sazonalidade: } s_t &= \gamma \frac {y_t}{(l_{t-1}-\phi b_{t-1})}+(1-\gamma)s_{t-1}, \end{align} \tag{5.9}\]
A Figura 5.9 expõe modelos de suavização exponencial com tendência amortecida e sazonalidade para a série de exportações do Brasil. O caso multiplicativo parece uma opção interessante com boa adequação aos períodos disponíveis, fazendo uma projeção à frente mais conservadora em comparação ao sem amortecimento.
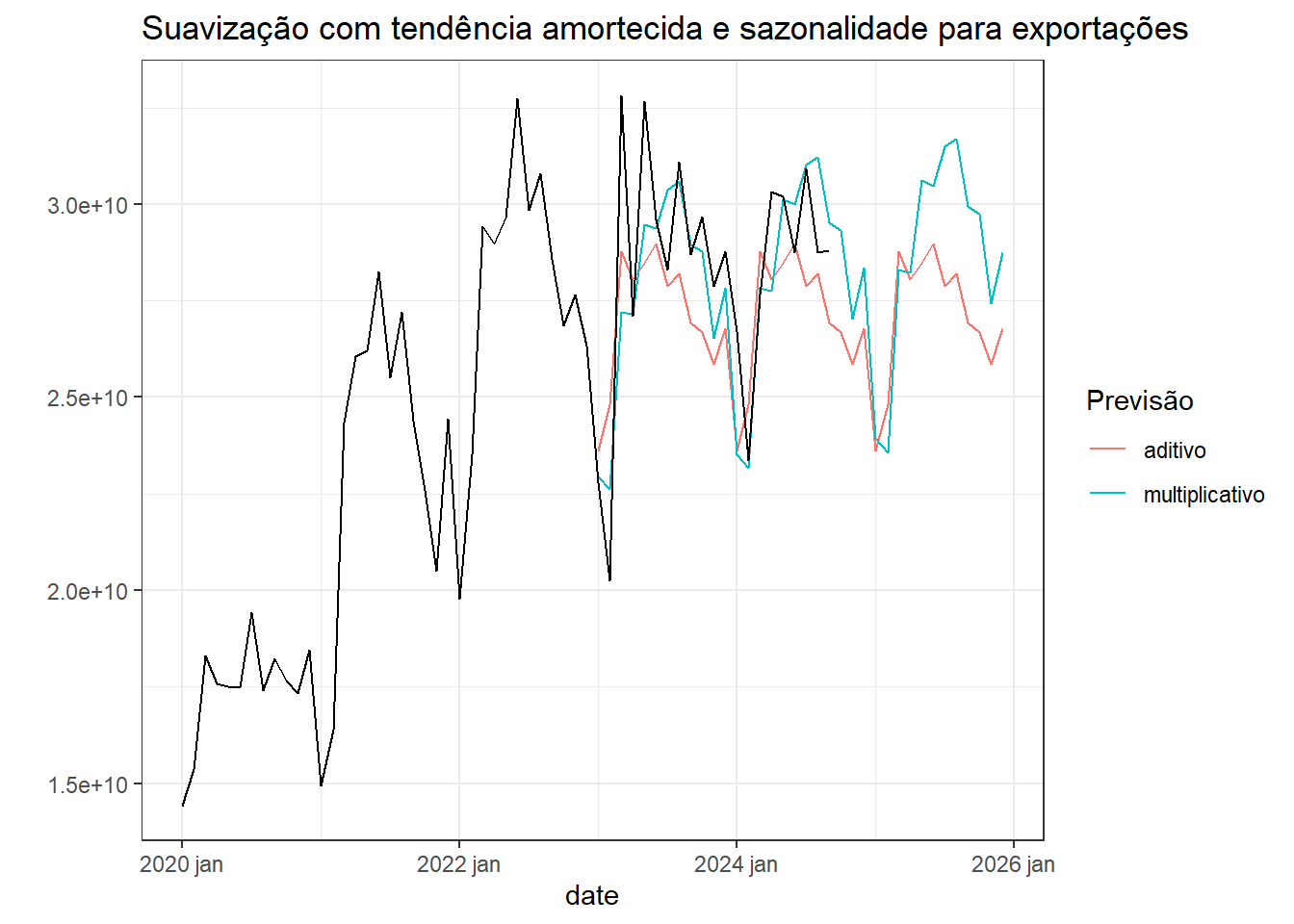
Para melhor avaliação dos resultados plotados para os modelos com sazonalidade com e sem amortecimento, a Tabela 5.5 resume os resultados das métricas de erro dos modelos para previsão de 2020 à frente, conformando que o modelo multiplicativo com amortecimento apresentou melhores resultados.
| modelo | RMSE | MAE | MAPE |
|---|---|---|---|
| aditivo sazonal | 2195052170 | 1834091706 | 6,62 |
| aditivo sazonal amort | 2384479823 | 2028508291 | 7,24 |
| mult sazonal | 1979894926 | 1550871084 | 5,54 |
| mult sazonal amort | 1961497440 | 1353227812 | 4,73 |
5.4 Modelos de ETS e definição de espaço de estados
Os modelos de suavização exponencial podem ser concebidos como modelos de espaço de estados, com uma equação de medição, que descreve os dados observados, e outras de estados, por exemplo as de nível, tendência e sazonalidade, que descrevem como os componentes ou estados mudam no horizonte de tempo. Outro aspecto importante ainda não abordado é que, além de considerar o erro aditivo, há a possibilidade de considerar o erro multiplicativo nos modelos de suavização exponencial.
Os modelos de suavização exponencial são geralmente denotados por ETS(E,T,S) para descrever as três componentes (erro, tendência, suavização). O erro pode ser aditivo ou multiplicativo, E={A,M}. A tendência pode ser não considerada (N), aditiva (A) ou aditiva amortecida (damped) (Ad), T ={N,A,Ad}. Por fim, a sazonalidade pode ser desconsiderada, ou pode ser aditiva ou multiplicativa, S={N,A,M}. Logo, há 18 modelos possíveis.
Retomando a suavização exponencial simples representada em componentes:
\[ \begin{align} \text{Equação de previsão: } \hat y_{t+h} &= l_t\\ \text{Equação de suavização: } l_t &= \alpha y_t + (1-\alpha)l_{t-1}.\\ \end{align} \]
Manipulando a Equação de suavização, tem-se o resultado apresentado na Equação 5.10.
\[ \begin{align} l_t &= l_{t-1} + \alpha(y_t-l_{t-1}) \\ &= l_{t-1} + \alpha e_t, \end{align} \tag{5.10}\]
onde \(e_t=y_t-l_{t-1}=y_t - \hat{y}_{t|t-1}\) é o resíduo no tempo \(t\). Pode-se, portanto, considerar que a observação de treino é igual ao nível anterior adicionado do erro, \(y_t=l_{t-1}+e_t\). Logo, deve-se assumir os resíduos como ruído branco, \(e_t = \varepsilon_t \sim NID(0,\sigma_\varepsilon^2)\) ou normalmente e identicamente distribuídos.
Quando o erro é multiplicativo no caso simples tem-se \(e_t=(y_t - \hat{y}_{t|t-1})/\hat{y}_{t|t-1}\).
A título de exemplo serão apresentados os modelos Holt-Winters aditivos com erro aditivo ETS(A,A,A) e multiplicativo ETS(M,A,A).
5.4.1 Modelo de Holt-Winters aditivo, ETS(A,A,A)
Para este caso, considerando o erro igual a \(\varepsilon_t =y_t - l_{t-1} + b_{t-1} + s_{t-m}\), tem-se o modelo exposto na Equação 5.11.
\[ \begin{align} y_t &= l_{t-1} + b_{t-1} + s_{t-m} + \varepsilon_t\\ l_t &= l_{t-1}+b_{t-1}+ \alpha \varepsilon_t\\ b_t &=b_{t-1} + \beta\varepsilon_t \\ s_t &= s_{t-m} + \gamma\varepsilon_t, \\ \end{align} \tag{5.11}\]
onde \(\beta=\beta^*\alpha\).
5.4.2 Modelo de Holt-Winters multiplicativo, ETS(M,A,A)
Para o caso com erro multiplicativo o erro com tendência e sazonalidade aditiva, o erro é calculado conforme a Equação 5.12.
\[ e_t= \frac{y_t - (l_{t-1} + b_{t-1} + s_{t-m})}{(l_{t-1} + b_{t-1} + s_{t-m} )} \tag{5.12}\]
O modelo fica conforme a Equação 5.13.
\[ \begin{align} y_t &= (l_{t-1} + b_{t-1} + s_{t-m} ) (1+\varepsilon_t)\\ l_t &= l_{t-1}+b_{t-1}+ \alpha (l_{t-1}-b_{t-1}-s_{t-m})\varepsilon_t\\ b_t &=b_{t-1} + \beta(l_{t-1} + b_{t-1} + s_{t-m} ) \varepsilon_t \\ s_t &= s_{t-m} + \gamma(l_{t-1} + b_{t-1} + s_{t-m} ) \varepsilon_t\\ \end{align} \tag{5.13}\]
Aqui foram apresentados apenas alguns modelos, sendo dois deles explicitados em notação de espaço de estados. RJ Hyndman e Athanasopoulos (2021) explicitam todos os 18 modelos possíveis de suavização exponencial com a notação de estado de espaços.
5.5 Previsão e intervalo de confiança com ETS
A previsão com modelos de ETS pode ser realizada iterando as equações à frente, \(t=T+1, ..., T+h\). Por exemplo, para o modelo ETS(M,A,A) a previsão para o primeiro período não disponível seria \(\hat y_{T+1} = l_{T} + b_{T} + s_{T}\).
O intervalo de confiança pode ser calculado conforme já exposto anteriormente, \(\hat{y}_{T+h|T} \pm1,96 \hat\sigma_h\), com 1,96 sendo o valor do quantil da distribuição \(z\) para 0,95 de confiança. O desvio-padrão depende do método ETS usado e a estimativa é bastante complexa. Rob Hyndman et al. (2008) fornece os cálculos detalhados.
A Figura 5.10 apresenta novamente as séries temporais de exportação, importação e produção de fertilizantes no Brasil em um mesmo painel gráfico, viabilizando a comparação entre estas. Observa-se de forma mais clara a preponderância das importações, especialmente nos últimos anos.
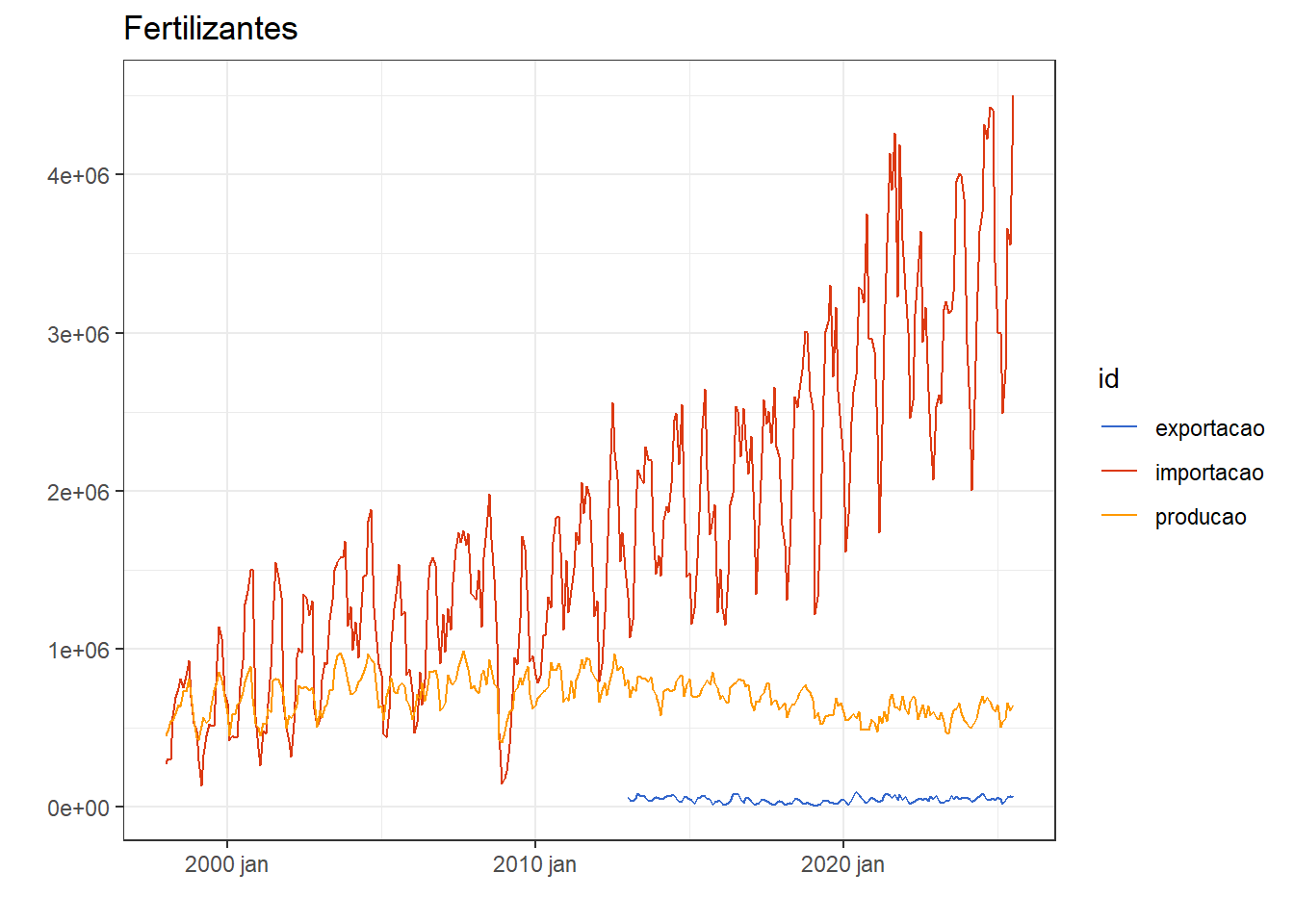
A série do volume de fertilizantes disponível no Brasil pode ser obtida somando os volumes de importação e exportação e subtraindo o volume de exportações. Tal série é plotada na Figura 5.11. Observa-se tendência de crescimento com variação sazonal homogênea no tempo. O ano de 2022 apresentou disponibilidade mais baixa, possivelmente em reflexo à pandemia.
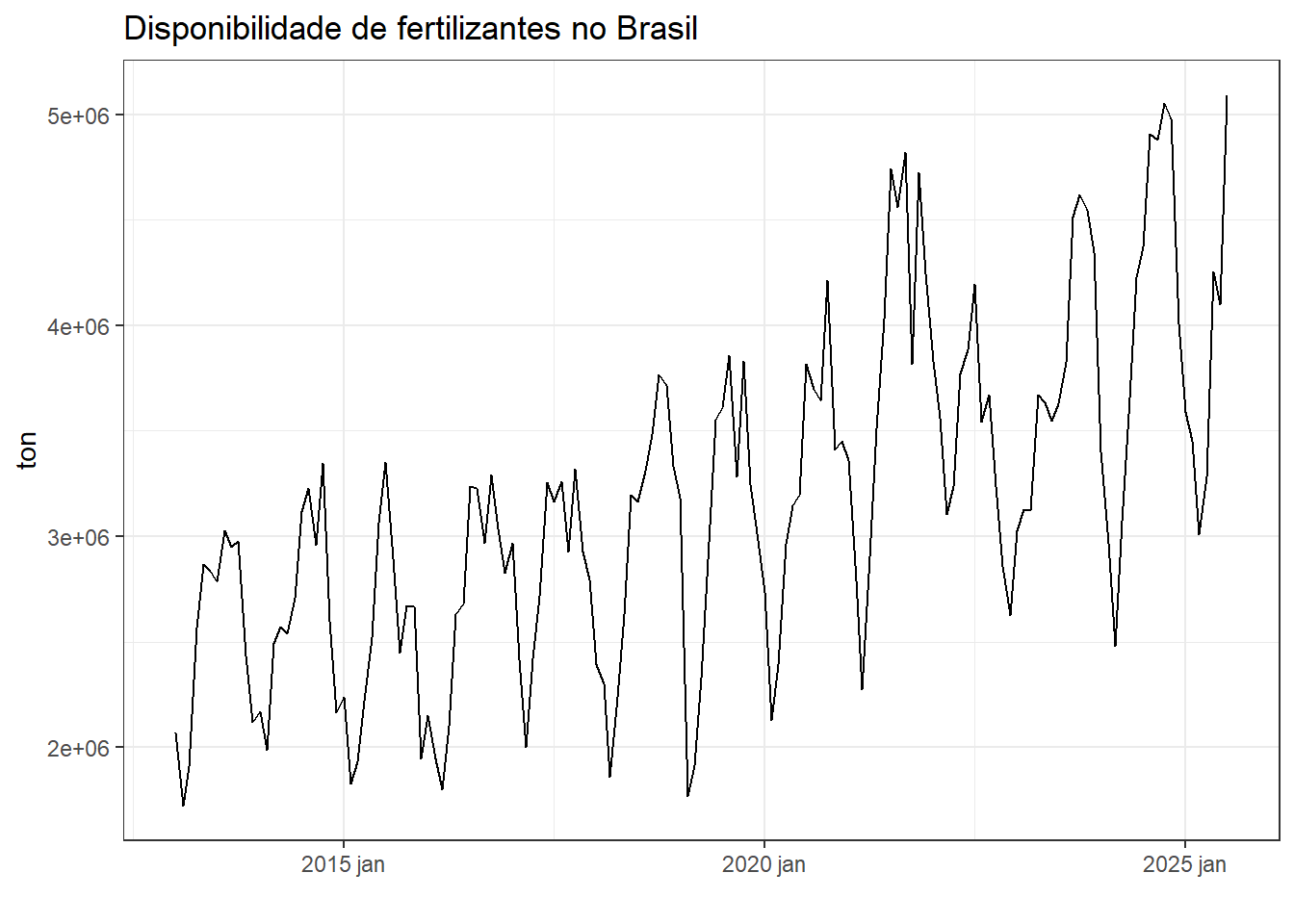
A Figura 5.12 expõe o gráfico da série de disponibilidade de fertilizantes para o Brasil. Observa-se aumento da disponibilidade ao longo dos anos e maior disponibilidade no segundo semestre dos anos de observação.
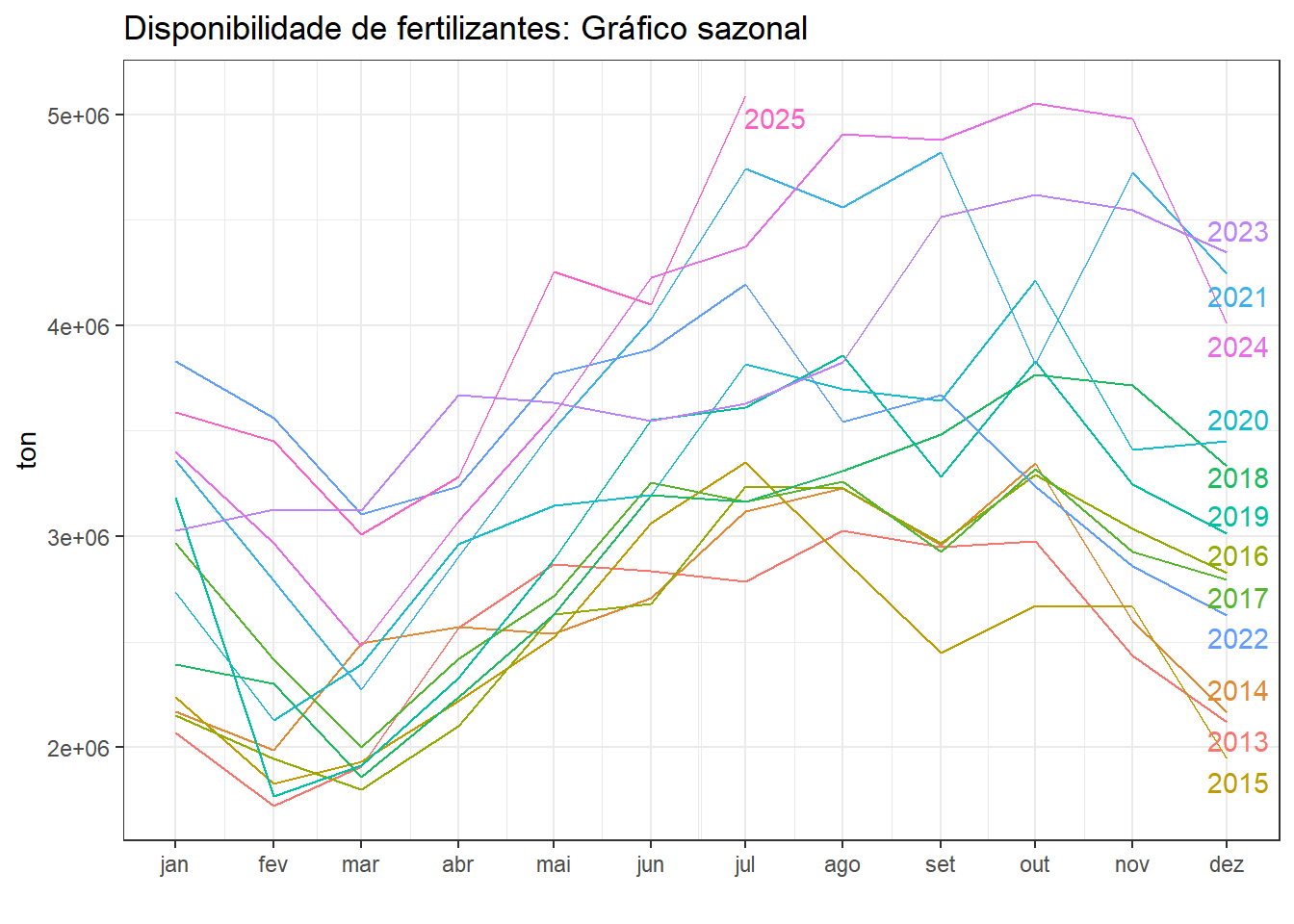
A Figura 5.13 exibe novamente a série com resultados de previsões a partir de 2022 para 4 distintos modelos ETS, aditivos e multiplicativos, com e sem amortecimento na tendência.
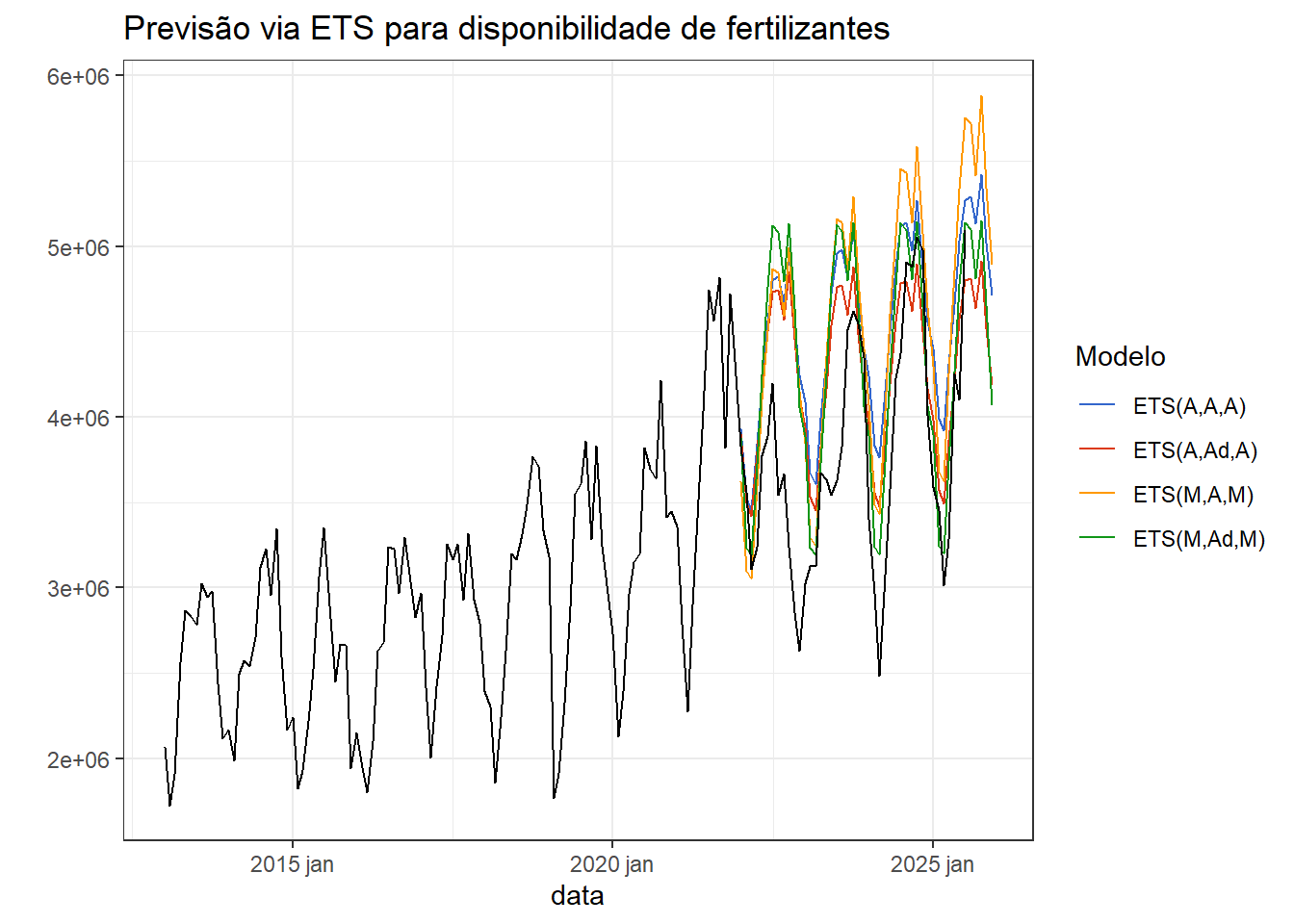
A Tabela 5.6 resume o desempenho dos modelos considerando os dados de 2022 à frente. Observa-se que o modelo aditivo com amortecimento, ETS(A,Ad,A), apresentou melhor resultado para todas as métricas de erro.
| modelo | RMSE | MAE | MAPE |
|---|---|---|---|
| ETS(A,A,A) | 835934,1 | 703718,4 | 20,76 |
| ETS(A,Ad,A) | 679257,2 | 538313,3 | 15,96 |
| ETS(M,A,M) | 838989,4 | 706033,3 | 20,06 |
| ETS(M,Ad,M) | 765089,4 | 573111,9 | 16,59 |
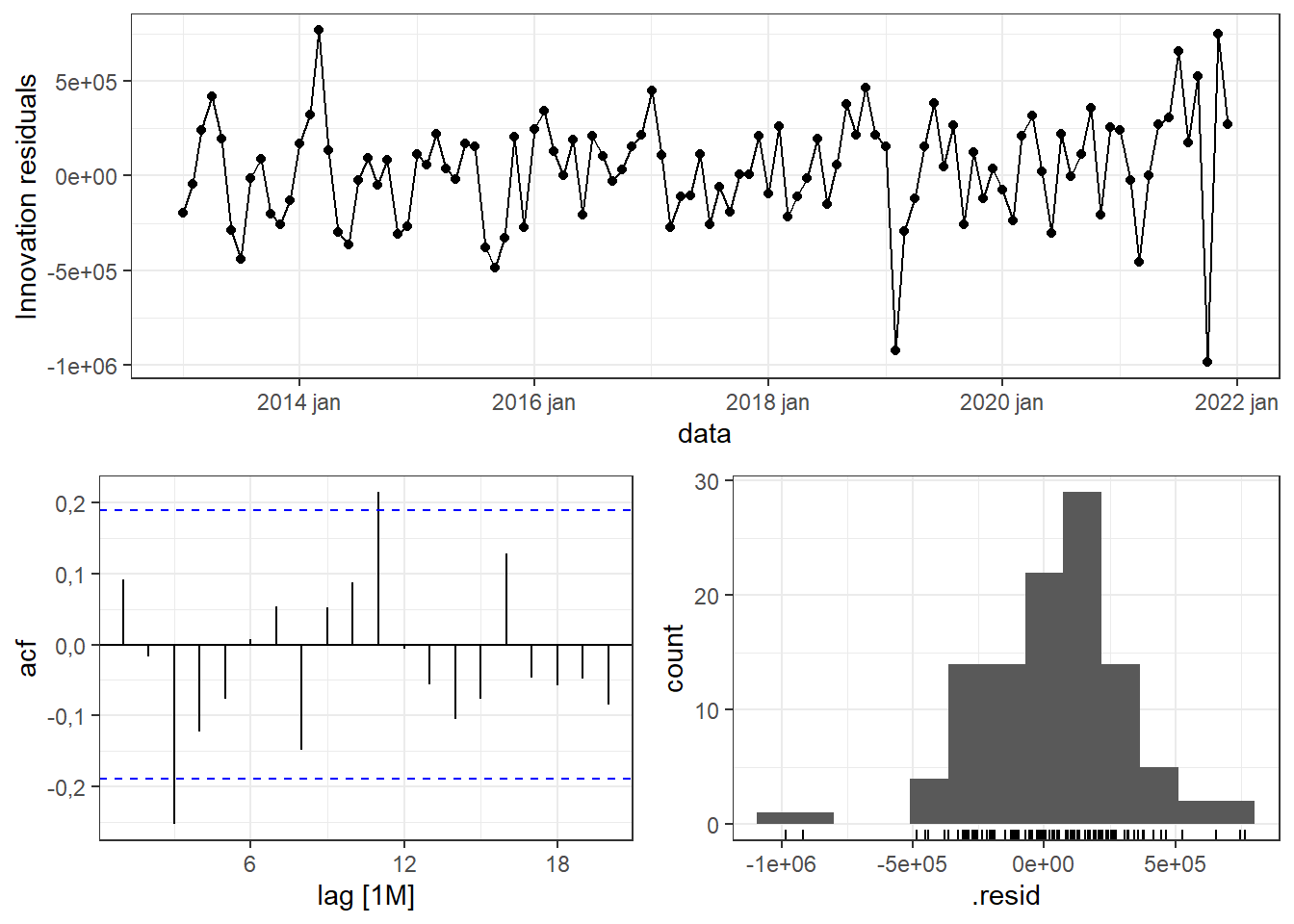
A Figura 5.14 expõe os gráficos de resíduos para o modelo ETS(A,Ad,A). Observa-se padrão aleatório na série residual, bom ajuste à normal e autocorrelação residual com significância para duas defasagens apenas. Para esclarecer se esta autocorrelação pode representar um problema, a Tabela 5.7 exibe o resultado do teste. Não se pode garantir a ausência de autocorrelação residual.
| estatística | pvalor |
|---|---|
| 32,92371 | 0,0343968 |
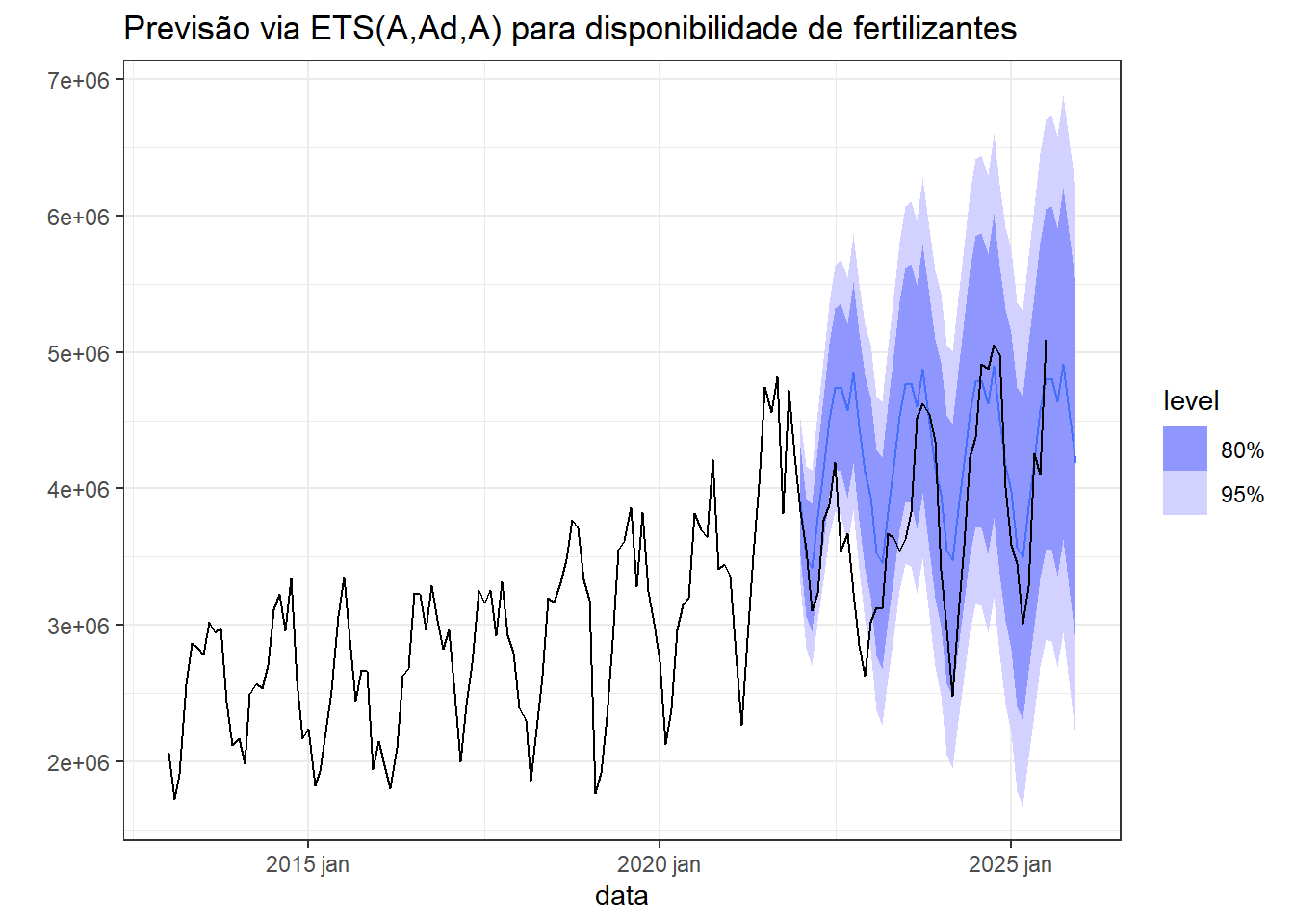
Finalmente, a Figura 5.15 expõe a previsão usando o modelo ETS(A,Ad,A) para quatro anos à frente. Observa-se boa aproximação às observações recentes, especialmente nos últimos dois anos.
5.6 Implementação em R
A seguir são apresentadas boa parte das implementações na linguagem R para obter os dados, gráficos e análises expostos no presente capítulo.
Carregando pacotes.
library(ggplot2)
library(tsibble)
library(fable)
library(fabletools)
library(forecast)
library(feasts)
library(lubridate)
library(dplyr)
library(tidyr)
library(knitr)
library(ipeadatar)
theme_set(theme_bw())Série do IPCA a partir de 2019. Esta série já foi apresentada no primeiro capítulo.
ipca_2019_ <- ipca_ts |>
filter_index("2019-01"~.)Modelo de suavização exponencial simples para a série do IPCA. Usa-se a função ETS e deve-se definir os tipos de termos de erro, tendência e sazonalidade com error, trend e season.
fit_ipca <- ipca_2019_ |>
model(ETS(ipca ~ error("A") + trend("N") + season("N")))
tidy(fit_ipca)[,-1]Previsão 5 meses à frente.
fc_ipca <- fit_ipca |>
forecast(h = 5)
fc_ipcaPlotando a série com os valores ajustados e a previsão.
fc_ipca |>
autoplot(ipca_2019_) +
geom_line(aes(y = .fitted), col="orangered",
data = augment(fit_ipca)) +
labs(y = "IPCA", x = "",
title="IPCA no Brasil a partir de 2019") +
guides(colour = "none")Valores ajustados e observados para os últimos meses da série.
augment(fit_ipca) |>
tail()População projetada no Brasil.
pop_br <- read.csv("populacao_br.csv", header=T)
pop_br <- pop_br |> filter(ano<=2010)
pop_ts <- pop_br |>
mutate(data = year(as.Date(as.character(ano),format="%Y"))) |>
select(-ano) |>
as_tsibble(index=data)pop_ts |> autoplot(pop) +
labs(title = "População projetada do Brasil",
y = "Pessoas", x="")Modelo de suavização exponencial com tendência (método de Holt).
fit <- pop_ts |>
model(
`Holt` = ETS(pop ~ error("A") + trend("A") + season("N")),
`Holt amortecido` = ETS(pop ~ error("A") +
trend("Ad", phi = 0.9) + season("N"))
)
tidy(fit)Previsão com modelos de Holt e Holt amortecido.
fc_pop <- fit |>
forecast(h = 15)
fc_pop |>
autoplot(pop_ts, level = NULL) +
labs(title = "População do Brasil",
y = "Milhões",x="") +
guides(colour = guide_legend(title = "Forecast"))Série de emissões de CO2.
emissoes <- read.csv("emissoes.csv", header = T)
emissoes_ts <- emissoes |>
mutate(Ano = year(as.Date(paste(Ano,"01 01"), format = "%Y %m %d"))) |>
as_tsibble(index = Ano)Modelo de Holt e Holt amortecido para Emissões de Co2 pela indústria.
emissoes_ts |>
model(
`Holt` = ETS(Industria ~ error("A") +
trend("A") + season("N")),
`Holt amortecido` = ETS(Industria ~ error("A") +
trend("Ad", phi = 0.90) + season("N"))
) |>
forecast(h = 15) |>
autoplot(emissoes_ts , level = NULL) +
labs(title = "Emissões de gases de efeito estufa pela indústria",
y = "Gg de CO2e",x="") +
guides(colour = guide_legend(title = "Previsão"))Seja a série de exportações do Brasil. A série já foi lida no capítulo 2. Gráfico sazonal da série.
exp_ts |> gg_season(Exp) +
labs(x="",y="Exportações [US$ FOB]: Gráfico sazonal")Modelos de suavização exponencial com sazonalidade aditiva e multiplicativa para exportações e com tendência amortecida ou não.
fit_export <- exp_ts |>
filter(year(date) <=2022) |>
model(
`ETS(A,A,A)` = ETS(Exp ~ error("A") + trend("A") +
season("A")),
`ETS(M,A,M)` = ETS(Exp ~ error("M") + trend("A") +
season("M")),
`ETS(A,Ad,A)` = ETS(Exp ~ error("A") + trend("Ad") +
season("A")),
`ETS(M,Ad,M)` = ETS(Exp ~ error("M") + trend("Ad") +
season("M"))
)
fc_export <- fit_export |> forecast(h = "3 years")
fc_export |>
autoplot(exp_ts |>
filter(year(date) >=2020), level = NULL) +
labs(title="Suavização com tendência e sazonalidade para a série de exportações",
y="") +
guides(colour = guide_legend(title = "Previsão"))A série de disponibilidade de fertilizantes é obtida considerando as séries de exportação, importação e produção de fertilizantes, já apresentadas no capítulo 4.
fert_ <- fert |>
pivot_wider(names_from=id,
values_from=valor)
fert_disp <- fert_ |>
filter_index("2013-01"~.) |>
mutate(disponibilidade = producao+importacao-exportacao)Plotando a série.
Gráfico sazonal.
fert_disp |>
gg_season(disponibilidade, labels = "right",
labels_repel = T)Estimando 4 modelos ETS para a disponibilidade até 2021.
fit_disp <- fert_disp |>
filter_index(~"2021-12") |>
model(
`ETS(A,A,A)` = ETS(disponibilidade ~ error("A") + trend("A") + season("A")),
`ETS(M,A,M)` = ETS(disponibilidade ~ error("M") + trend("A") + season("M")),
`ETS(A,Ad,A)` = ETS(disponibilidade ~ error("A") + trend("Ad") + season("A")),
`ETS(M,Ad,M)` = ETS(disponibilidade ~ error("M") + trend("Ad") + season("M"))
)Previsão de 2022 até o fim de 2025.
fc_disp <- fit_disp |>
forecast(h = "4 years")
fc_disp |>
autoplot(fert_disp, level = NULL) +
labs(title="Previsão via ETS para disponibilidade de fertilizantes",
y="") +
guides(colour = guide_legend(title = "Modelo"))Avaliando a acuracidade dos modelos usando dados de 2022 até junho de 2025.
accuracy(fc_disp, fert_disp |>
filter_index("2022-01"~.)) |>
select(.model, RMSE, MAE, MAPE)Gráficos de resíduos do melhor modelo.
fit_disp |>
select(`ETS(A,Ad,A)`) |>
gg_tsresiduals()Teste de Ljung-Box para os resíduos do melhor modelo. Consideram-se 4 termos no modelo no caso amortecido.
augment(fit_disp |>
select(`ETS(A,Ad,A)`)) |>
features(.innov, ljung_box, dof = 4, lag = 24)Previsão com intervalo de confiança para o melhor modelo.
fc_disp |>
filter(.model=="ETS(A,Ad,A)") |>
autoplot(fert_disp) +
labs(title="Previsão via ETS(A,Ad,A) para disponibilidade de fertilizantes",
y="")5.7 Exercícios propostos
- Seja a série de produção de grãos. Separe os últimos cinco anos para testar o modelo. Aplique um modelo de suavização exponencial com tendência. Considere também o caso amortecido com \(\phi = 0,9\) e \(\phi=0,95\).
- Avalie os resíduos dos modelos obtidos.
- Calcule as métricas de ajuste para os dados de teste e escolha o melhor modelo.
- Seja a série de volume de exportações do Brasil exposta neste capítulo. Considerando os modelos obtidos de suavização exponencial com sazonalidade aditiva e multiplicativa e com tendência simples ou amortecida, avalie os resíduos de todos os modelos. Calcule as métricas de teste para os dados de 2023 à frente e escolha o melhor modelo.
Seja a série de produção de asfalto obtida conforme segue a partir da série de derivados do petróleo do capítulo 4.
asfalto <- petro_ts |>
filter(derivado == "asfalto") |>
select(!derivado)
asfalto |> autoplot(volume)- Filtre a série até o fim do ano de 2023 e estime 8 modelos ETS usando sazonalidade aditiva ou multiplicativa, tendência com ou sem amortecimento e erro aditivo ou multiplicativo e plote os resultados.
- Faça a previsão 2 anos à frente para a série.
- Avalie o desempenho dos modelos considerando observações disponíveis de 2024.
- Avalie os resíduos do modelo que apresentou menor erro.
- Faça o teste de Ljung-Box para o melhor modelo.
Seja a série de passageiros em vôos do Brasil já apresentada no capítulo 3.
- Filtre a série até o fim do ano de 2017 e estime 8 modelos ETS usando sazonalidade aditiva ou multiplicativa, tendência com ou sem amortecimento e erro aditivo ou multiplicativo e plote os resultados.
- Faça a previsão 2 anos à frente para a série.
- Avalie o desempenho dos modelos considerando observações disponíveis de 2024.
- Avalie os resíduos do modelo que apresentou menor erro.
- Faça o teste de Ljung-Box para o melhor modelo.